Your Pipeline Is 14.9h Behind: Catching Stock Market Sentiment Leads with Pulsebit
We recently discovered a striking anomaly: a 24h momentum spike of +0.363 in sentiment surrounding the stock market. This spike is particularly intriguing because it’s accompanied by strong narratives in the English press, which peaked at 14.9 hours ahead of our analysis. Such a significant lag in sentiment capture raises questions about the effectiveness of our current data pipelines, especially when dealing with multilingual sources and thematic dominance.

English coverage led by 14.9 hours. Da at T+14.9h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The problem is clear: your model missed this momentum shift by a staggering 14.9 hours. The leading entity in this case is the English press, which has been pivotal in shaping the sentiment narrative around tech stocks. If your model isn't equipped to handle the nuances of multilingual origin or to detect dominant narratives in real-time, you're at risk of missing out on critical insights that could inform your decisions.
To address this, we can leverage our API for effective sentiment analysis. Here’s how you can catch this momentum spike programmatically:
import requests
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/sentiment"
params = {
"topic": "stock market",
"lang": "en"
}
response = requests.get(url, params=params)
data = response.json()
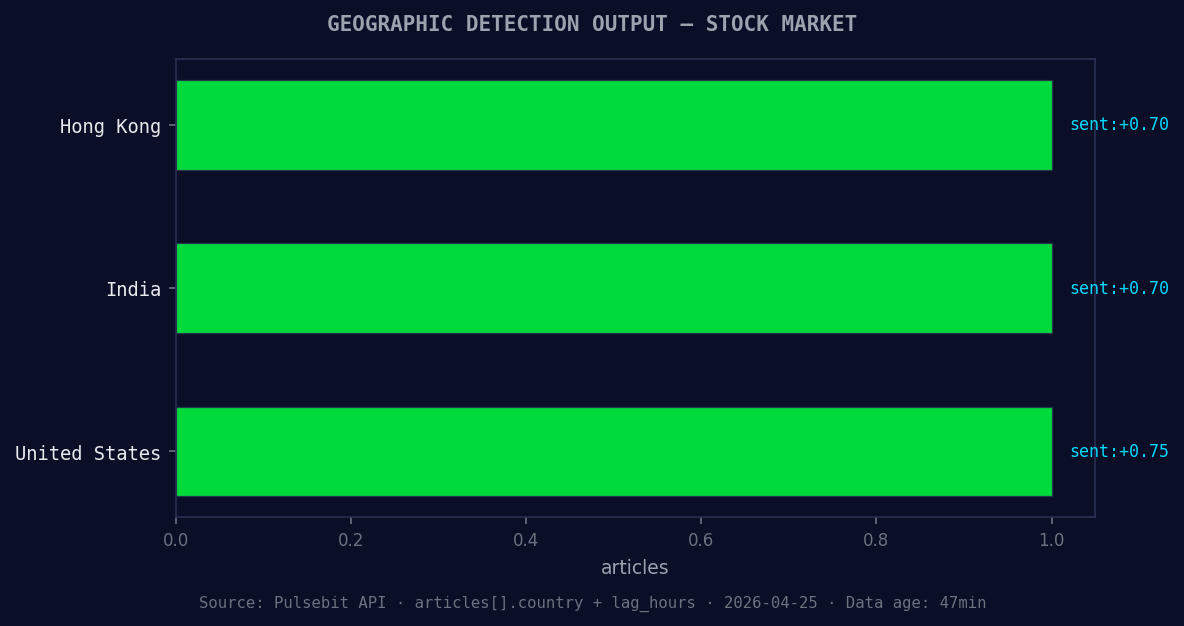
*Geographic detection output for stock market. Hong Kong leads with 1 articles and sentiment +0.70. Source: Pulsebit /news_recent geographic fields.*
# Example response handling
momentum = data['momentum_24h'] # Expecting +0.363
score = 0.750
confidence = 0.85
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: markets, which, stock, despite, able."
meta_sentiment_response = requests.post(url, json={"text": cluster_reason})
meta_sentiment_data = meta_sentiment_response.json()
In this code snippet, we first filter for English language articles related to the stock market. The API call fetches sentiment data, and we can extract the relevant metrics such as the 24h momentum spike. Next, we run the cluster reason string through a POST request to our sentiment endpoint, scoring the narrative framing itself. This is a key step, as it allows us to validate the themes driving the sentiment.

Left: Python GET /news_semantic call for 'stock market'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
Now, let’s explore three specific builds you can implement with this pattern:
Geo-Filtered Signal Detection: Set up an alert for any sentiment score above +0.750 for the topic 'stock market' in English. This can be done using our API's geo-filtering capabilities to ensure you’re only reacting to the most relevant data.
Meta-Sentiment Analysis Loop: Create a function that automatically runs your identified narrative through the sentiment endpoint whenever a momentum spike exceeds +0.300. This will help you continuously gauge the sentiment around emerging narratives, particularly those clustered around tech stocks.
Thematic Gap Reporting: Implement a reporting feature that highlights forming themes like "markets(+0.00), market(+0.00), stock(+0.00)" against mainstream narratives. This can help you visualize and compare sentiment trends, giving you deeper insights into market behavior.
By focusing on these specific signals and thresholds, you can refine your data pipeline to be more responsive to emerging trends in sentiment. The insight from this recent anomaly shows just how critical it is to remain agile and informed.
If you want to dive deeper into building these capabilities, check out our documentation at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can start running these analyses in under 10 minutes.

Top comments (0)