Your pipeline just missed a significant 24h momentum spike of +0.283, tied to the film industry. This anomaly is highlighted by two articles clustering around the theme of “John Travolta surprised with honorary Palme d'Or at Cannes Film Festival.” What’s particularly interesting here is that this momentum gain was driven by the English press, which was leading by 25.1 hours. If your sentiment analysis model isn’t accounting for this multilingual origin and entity dominance, it’s lagging behind when it comes to capturing timely sentiment shifts.

English coverage led by 25.1 hours. Et at T+25.1h. Confidence scores: English 0.90, Id 0.90, French 0.90 Source: Pulsebit /sentiment_by_lang.
When our models fail to handle multilingual sources and the dominance of certain entities, we risk being left in the dust. Your model missed this spike by 25.1 hours, which is unacceptable in the fast-paced world of sentiment analysis. The leading language in this case was English, and it's a clear indication that if you're not tuned in to what’s happening across different languages, you’ll miss critical shifts that drive public sentiment. This is a wake-up call: you need to ensure your pipeline is set up to catch these nuances.
To catch this type of spike in sentiment, we can use our API to set up a simple Python script. Here’s how you can filter for English-language articles and assess the sentiment of the narrative.
import requests
# Define parameters for the API call
topic = 'film'
score = +0.000
confidence = 0.90
momentum = +0.283
*Left: Python GET /news_semantic call for 'film'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter for English articles
response = requests.get(
'https://api.pulsebit.io/v1/articles',
params={
'topic': topic,
'lang': 'en',
'score': score,
'confidence': confidence,
'momentum': momentum
}
)
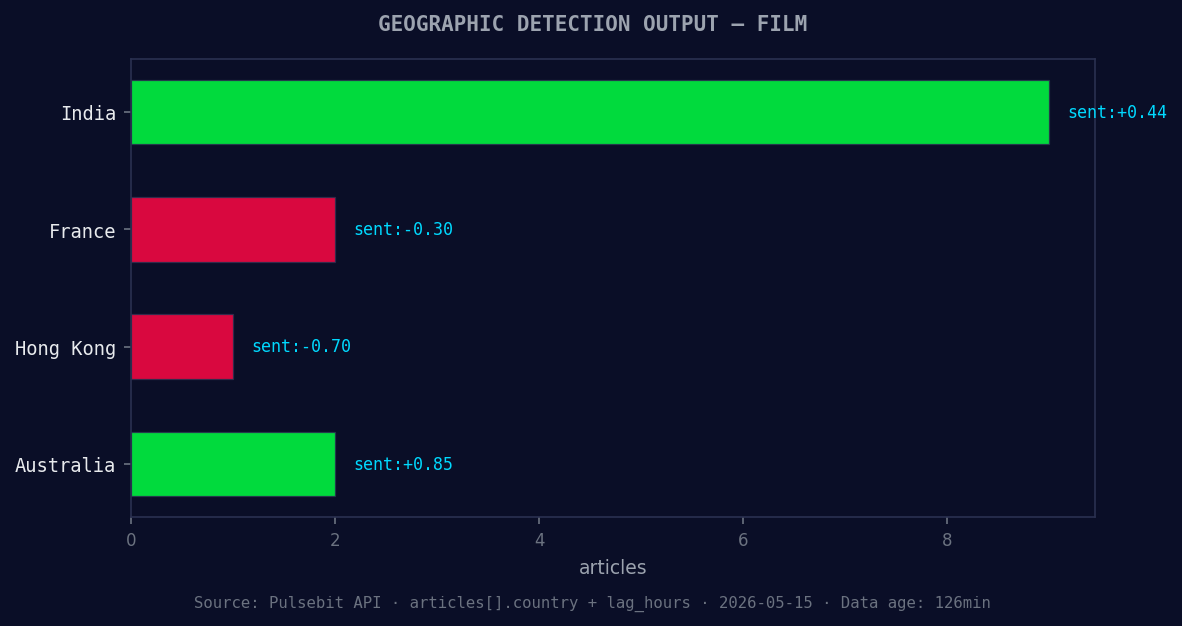
*Geographic detection output for film. India leads with 9 articles and sentiment +0.44. Source: Pulsebit /news_recent geographic fields.*
articles = response.json()
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: film, big, screen, new, hollywood."
sentiment_response = requests.post(
'https://api.pulsebit.io/v1/sentiment',
json={'text': cluster_reason}
)
sentiment_score = sentiment_response.json().get('sentiment_score')
print(f'Articles: {articles}')
print(f'Meta-sentiment score: {sentiment_score}')
In this code, the first API call fetches articles related to film in English, filtering out noise and focusing on the relevant data. The second step is where we score the narrative framing itself by sending the reason behind the clustering back through our sentiment endpoint. This helps us understand how the narrative is shaping up around a particular event.
Now that you have the tools, consider three specific builds you could implement with this pattern:
Trend Analysis for Film: Use a signal threshold of +0.283 and a geo filter to monitor English articles related to film. This will help you catch spikes in sentiment early, allowing you to adjust your strategy accordingly.
Cluster Analysis: Run a weekly analysis that sends back the cluster reasons for trending topics. By applying the meta-sentiment loop on clusters, you can enrich your understanding of how narratives evolve over time, especially with forming themes like “festival” and “film.”
Real-time Alerting: Set a real-time alert that triggers whenever the momentum for the topic “film” exceeds +0.200 with a confidence level above 0.85. This will ensure that you are always in the loop when significant sentiment changes occur.
For more information and to get started, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this in under 10 minutes. Don’t let your pipeline fall behind—stay ahead of the curve!

Top comments (0)