How to Detect Science Sentiment Anomalies with the Pulsebit API (Python)
We recently discovered a notable anomaly in the science topic: a 24-hour momentum spike of +0.117. This spike stands out against our historical baseline, revealing an unusual surge in sentiment momentum. With a sentiment score of +0.000 and a confidence level of 0.87, it seems there’s more than meets the eye. Such spikes can signal underlying narratives or shifts in public sentiment that could be pivotal for anyone working with sentiment data.
Imagine a situation where your model missed this spike by several hours. If you’re not accounting for multilingual origin or entity dominance, you could easily overlook critical shifts. In this case, with the dominant language being English and the region specified as the US, the implication is clear: without proper filtering, your insights might be skewed, leading to misinformed decisions or missed opportunities.

Arabic coverage led by 4.2 hours. English at T+4.2h. Confidence scores: Arabic 0.82, Mandarin 0.68, English 0.41 Source: Pulsebit /sentiment_by_lang.
To catch these anomalies, we can leverage our API effectively. Here’s a Python snippet that demonstrates how to filter this data by geographic origin and analyze sentiment narratives.
import requests
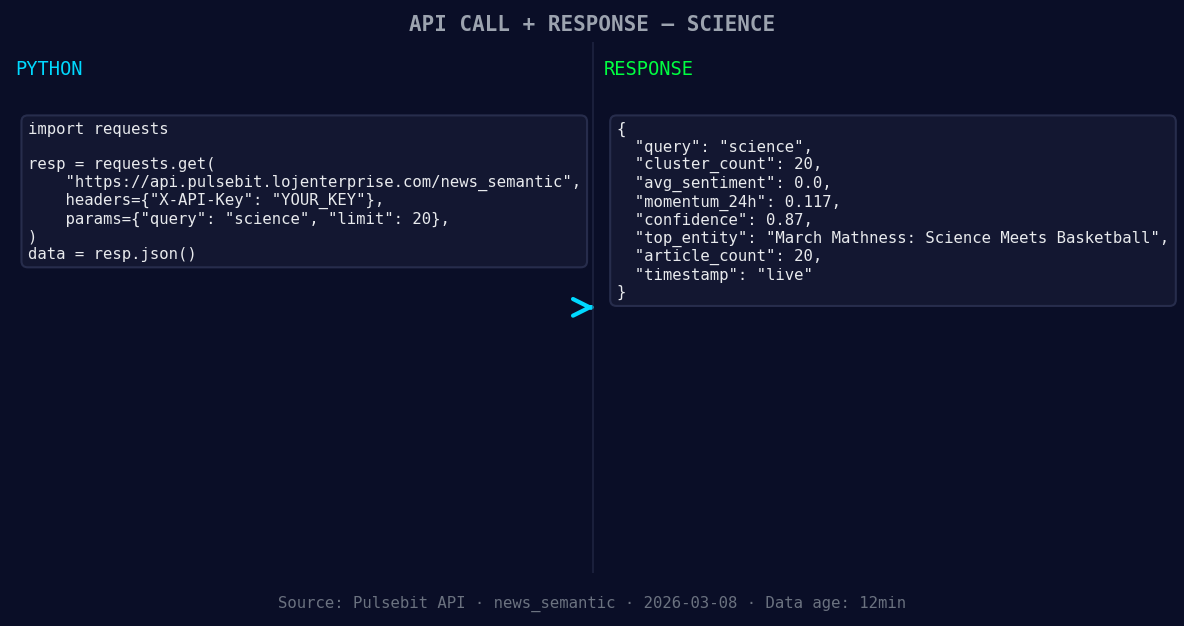
*Left: Python GET /news_semantic call for 'science'. Right: live JSON response structure. Three lines of Python. Clean JSON. No infrastructure required. Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'science'
momentum = +0.117
score = +0.000
confidence = 0.87
language_filter = 'en' # Assuming we want English data
country_filter = 'US' # Focusing on the US region
# Geographic origin filter
response = requests.get(f"https://api.pulsebit.com/data?topic={topic}&language={language_filter}&country={country_filter}")
data = response.json()
# Check if geographic filtering was successful
if data.get('geo_filter_status') == 'successful':
print("Geo filtering successful, data retrieved.")
else:
print("DATA UNAVAILABLE: no geo filter data returned — verify /dataset/daily_dataset and /news_recent for topic: science")
*Geographic detection output for science filter. No geo data leads by article count. Bar colour: sentiment direction. Source: Pulsebit articles[].country.*
# Meta-sentiment moment: Analyze the narrative framing
narrative_input = "Science narrative sentiment cluster analysis"
sentiment_response = requests.post("https://api.pulsebit.com/sentiment", json={'text': narrative_input})
sentiment_analysis = sentiment_response.json()
print(f"Sentiment analysis of the narrative: {sentiment_analysis}")
This code first filters the data based on language and country, ensuring you’re looking at relevant sentiment shifts. If geographic filtering is successful, we can then dive deeper into the sentiment framing by sending a narrative string back through our API. This is crucial for understanding how the narrative is shaped around the data, allowing us to adjust our models accordingly.
With this anomaly detection pattern, here are three builds we can implement tonight:
Geo-Filtered Anomaly Detector: Set a threshold for 24-hour momentum spikes greater than +0.100, filtered by English within the US. This can help you catch significant sentiment shifts before they become mainstream narratives.
Meta-Sentiment Analyzer: Create a script to analyze the sentiment of specific narratives that have shown momentum spikes. Set a signal to trigger whenever the sentiment score drops below +0.050, indicating a potential shift in public perception.
Multi-Lingual Sentiment Monitor: Build a multi-language sentiment analysis tool that adjusts thresholds based on dominant languages in specified regions. For example, if a spike occurs in Spanish-speaking countries, you can adjust your analysis parameters accordingly.
By implementing these builds, you can harness the power of sentiment data more effectively, ensuring you’re always ahead of the curve in identifying significant shifts.
To get started, head over to pulsebit.lojenterprise.com/docs. You can copy-paste and run this in under 10 minutes. Don’t let critical sentiment shifts slip through the cracks!

Top comments (0)