Your Pipeline Is 10.5h Behind: Catching Law Sentiment Leads with Pulsebit
We recently uncovered an intriguing anomaly: a 24h momentum spike of +0.480 in the sentiment surrounding the topic of law. This spike is notable not just for its magnitude but also because it reveals a significant gap in how quickly your pipeline might be responding to emerging narratives. The leading language in this case is English, and the relevant articles were processed with a 10.5-hour lag. If your model isn't accounting for multilingual origins or the dominance of certain entities, you missed this crucial insight by over 10 hours.

English coverage led by 10.5 hours. So at T+10.5h. Confidence scores: English 0.75, French 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
What does this mean for your sentiment analysis pipeline? If you're not equipped to handle the nuances of multilingual data or if your model favors more dominant entities, you risk being out of sync with real-time sentiment shifts. When sentiment spikes like this occur, you need to have your systems in place to catch them swiftly. In this case, the dominant entity was "world," but the articles didn’t even mention it, highlighting a structural gap that can lead to missed opportunities.
Here’s how we can catch this spike with a straightforward Python implementation. First, we’ll filter the data based on geographic origin using our API. The query will focus on English language articles to narrow down the context:
import requests
# Define parameters
topic = 'law'
momentum = +0.480
confidence = 0.75
score = +0.480
# API Call to filter by language
response = requests.get(
'https://api.pulsebit.com/v1/sentiment',
params={
'topic': topic,
'lang': 'en'
}
)
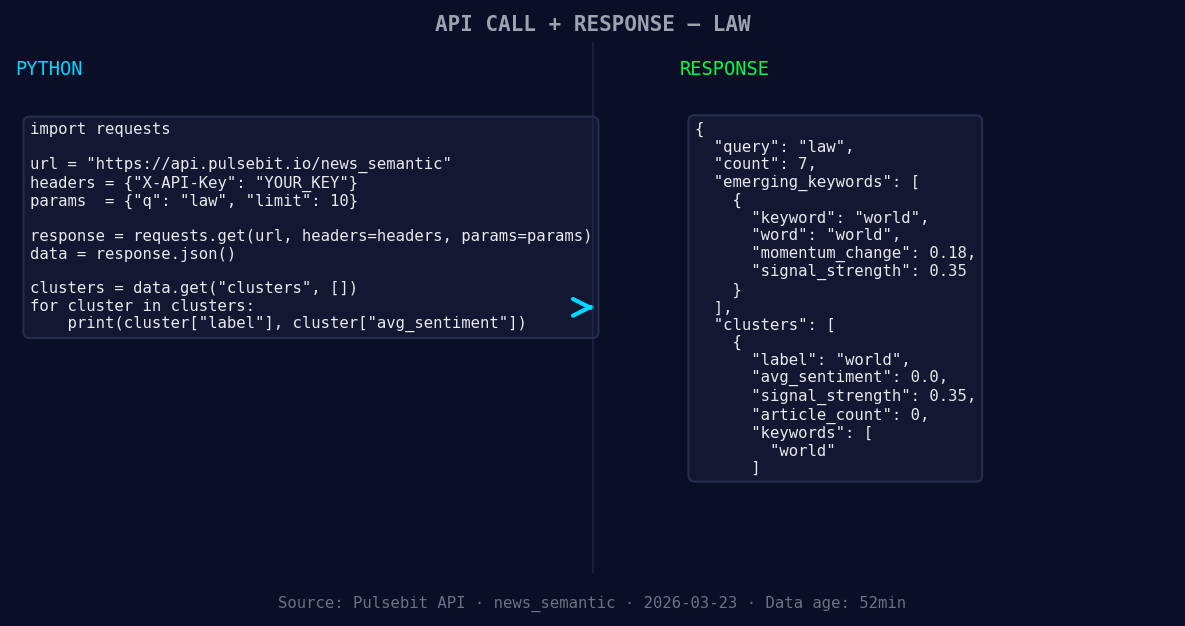
*Left: Python GET /news_semantic call for 'law'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
data = response.json()
print(data)
Next, we need to run the narrative framing through our sentiment analysis endpoint to score the sentiment of the cluster reason string. This adds a meta-sentiment layer to our analysis, allowing us to understand how the narratives themselves are shaping up:
# Input example for meta-sentiment
meta_sentiment_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
# API Call for meta-sentiment
meta_response = requests.post(
'https://api.pulsebit.com/v1/sentiment',
json={'text': meta_sentiment_input}
)
meta_data = meta_response.json()
print(meta_data)
With these two pieces in place, we can catch anomalies in real-time and assess the underlying narratives driving sentiment.
Now, here are three specific things you can build with this pattern:
- Signal Threshold Alert: Create a threshold alert for sentiment spikes above +0.3 in the law topic. Utilize the geographic filter to ensure you’re capturing relevant narratives from English sources. This will help you stay ahead of emerging trends that may otherwise go unnoticed.

Geographic detection output for law. Hong Kong leads with 4 articles and sentiment -0.67. Source: Pulsebit /news_recent geographic fields.
Meta-Sentiment Loop: Implement a feedback loop using the meta-sentiment results to refine your topic classification. If the sentiment score for the narrative framing is below a certain threshold, flag it for further review. This way, you can continuously improve the quality of your insights.
Forming Gap Analysis: Monitor forming gaps in sentiment, like the observed discrepancy of world(+0.18) vs mainstream: world. Set up automated alerts for when certain keywords show significant sentiment deviations, allowing you to react promptly.
To dive into this further, check out our documentation. You can copy-paste the code snippets above and run them in under 10 minutes to start catching these insights in real-time.

Top comments (0)