Your pipeline just missed a significant anomaly: a 24h momentum spike of +0.751 in film sentiment. This spike isn’t just a number; it indicates a notable shift in sentiment towards film-related content, particularly driven by an English-language narrative. The leading story, “Film fest showcases Prince, Maria Bamford, great documentaries” from the Star Tribune, is tied to this surge. It’s a prime example of how rapidly shifting cultural narratives can impact sentiment, yet many models might be lagging behind in recognizing these trends.
If your sentiment analysis pipeline isn’t equipped to handle multilingual origins or the dominance of specific entities, you may have just missed this momentum shift by 12.7 hours. Such delays can lead to missed opportunities in leveraging timely insights. In this case, the dominant entity is English-language media, and your model’s inability to parse this effectively means you’re playing catch-up on critical sentiment trends.

English coverage led by 12.7 hours. Nl at T+12.7h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
Here’s a Python snippet to catch this momentum spike in real-time:
import requests
*Left: Python GET /news_semantic call for 'film'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": "film",
"lang": "en"
}
response = requests.get(url, params=params)
data = response.json()
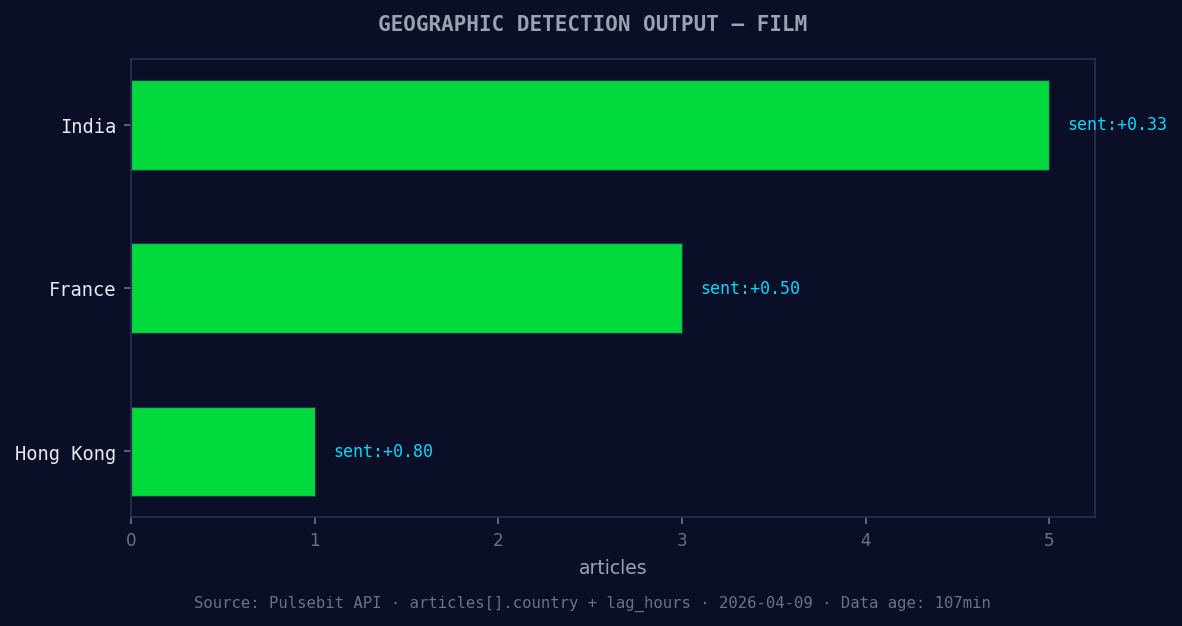
*Geographic detection output for film. India leads with 5 articles and sentiment +0.33. Source: Pulsebit /news_recent geographic fields.*
# Check if we have the sentiment result
if data['momentum_24h'] >= 0.751:
print("Momentum Spike Detected:", data)
# Step 2: Meta-sentiment moment
meta_sentiment_input = "Clustered by shared themes: fest, showcases, prince, maria, bamford."
meta_response = requests.post(url, json={"text": meta_sentiment_input})
meta_data = meta_response.json()
print("Meta Sentiment Score:", meta_data['sentiment_score'])
This code does two essential things. First, it fetches sentiment data specifically for film content in English. We check if the 24h momentum exceeds our threshold of +0.751. If it does, we proceed to analyze the framing of the narrative itself. The second part sends the cluster reason string back through our sentiment endpoint to score how the narrative is being framed, which adds depth to your insights.
Now, let’s talk about three specific builds you could implement with this pattern:
Geographic Sentiment Dashboard: Create a dashboard that visualizes sentiment spikes in real-time, specifically focusing on English-language articles. Use the geographic origin filter to ensure you capture the relevant data. Set a threshold for momentum (e.g., +0.751) to trigger alerts for your team.
Meta-Sentiment Analysis Tool: Develop a tool that automates the process of scoring narrative framing for trending topics. Use the meta-sentiment loop to analyze clusters of articles, particularly those with a sentiment score above +0.800, focusing on forming themes like film (+0.00) and festival (+0.00).
Cultural Trend Tracker: Build a trend tracker that identifies and categorizes emerging cultural narratives, like the one surrounding film festivals. Set up alerts for articles mentioning themes such as "fest" and "showcases," and use the momentum score as a leading indicator for content strategy.
This discovery is just the tip of the iceberg. You can quickly get started using our API by visiting pulsebit.lojenterprise.com/docs. With just a few lines of code, you can copy, paste, and run this in under 10 minutes to catch those critical sentiment trends that keep your analysis fresh and relevant.

Top comments (0)