Your Pipeline Is 21.5h Behind: Catching Startups Sentiment Leads with Pulsebit
We recently spotted an anomaly: a 24h momentum spike of -0.255 in sentiment surrounding the topic of startups. This isn’t just noise; it highlights a significant opportunity to catch emerging trends before they become mainstream. As developers, we need to be vigilant about these signals, especially when they originate from multilingual sources.

Spanish coverage led by 21.5 hours. Da at T+21.5h. Confidence scores: Spanish 0.90, English 0.90, French 0.90 Source: Pulsebit /sentiment_by_lang.
The structural gap here is glaring: your model may have missed this critical insight by a staggering 21.5 hours, primarily because it couldn't handle the Spanish-language articles leading the charge. This means that while your pipeline was busy processing English-language content, vital sentiment changes were brewing elsewhere. The leading language was Spanish, and the lack of support for multilingual contexts can leave you out of the loop.
To get ahead, we can leverage our API to capture these insights directly. Below is a sample Python snippet that highlights how to tap into this. First, we need to filter the sentiment data by geographic origin using the language parameter:

Geographic detection output for startups. Hong Kong leads with 1 articles and sentiment -0.60. Source: Pulsebit /news_recent geographic fields.
import requests
# Define the parameters for the request
topic = 'startups'
score = -0.255
confidence = 0.90
momentum = -0.255
# Make the API call to query by Spanish language
response = requests.get('https://api.pulsebit.com/v1/sentiment', params={
'topic': topic,
'lang': 'sp'
})
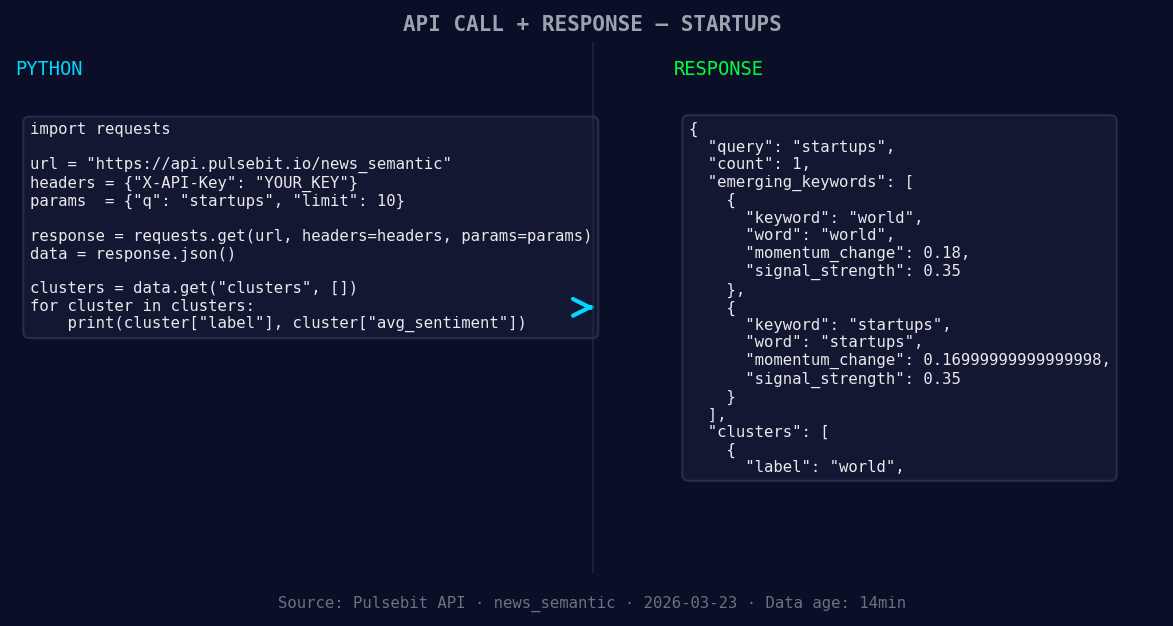
*Left: Python GET /news_semantic call for 'startups'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
data = response.json()
print(data)
Next, we must evaluate the framing of the narrative around this anomaly. Let's run the cluster reason string through our sentiment analysis endpoint. The input is derived from the API reason: "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
Here’s how to do that:
# Define the input for the meta-sentiment analysis
meta_sentiment_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
# Make a POST request to analyze the narrative framing
meta_response = requests.post('https://api.pulsebit.com/v1/sentiment', json={
'text': meta_sentiment_input
})
meta_data = meta_response.json()
print(meta_data)
Now that we’ve set the groundwork, here are three specific builds you should consider implementing tonight.
Geo-Filtered Trends: Set up a scheduled task that runs hourly sentiment checks specifically for Spanish articles about startups. Use the endpoint with the language parameter as shown above. Any score below -0.20 should trigger an alert.
Meta-Sentiment Loop: Create a function to automatically submit any anomalous sentiment narratives back to the sentiment analysis endpoint. For instance, loop through articles that fall under the "world" cluster and analyze their framing. If the sentiment score dips below -0.25, push those stories into your pipeline for deeper investigation.
Forming Themes Tracker: Leverage the forming themes of "world(+0.18)" and "startups(+0.17)" to build an analytics dashboard. Monitor sentiment spikes and declines against mainstream metrics, using the
POST /sentimentendpoint to generate alerts when these thresholds are crossed.
With these builds, you can stay ahead of the curve and ensure your pipeline isn’t lagging behind.
To get started, head to our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the provided code snippets and run them in under 10 minutes.

Top comments (0)