Your Pipeline Is 11.5h Behind: Catching Law Sentiment Leads with Pulsebit
We recently stumbled upon an intriguing anomaly: a 24h momentum spike of +0.199 in sentiment around the topic of law. What's particularly striking is that while English press has led this spike with an 11.5h head start, the semantic cluster around "world" has yielded no articles. This gap in our understanding—where sentiment is rising but not reflected in available content—raises serious questions about the effectiveness of our pipelines, especially when it comes to multilingual origins and entity dominance.

English coverage led by 11.5 hours. Da at T+11.5h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
The problem here is clear: if your model doesn't accommodate variations in language or the prominence of different entities, you could be missing critical insights by over 11 hours. In this case, the leading language was English, and the dominant entity was the topic of law. If you’re relying solely on traditional models, you might find yourself trailing behind, missing the nuances that could inform your strategies.
Here's how we caught this anomaly in code. We utilized our API to filter by language and establish the sentiment score based on the observed spike.
import requests
*Left: Python GET /news_semantic call for 'law'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/sentiment"
params = {
"topic": "law",
"lang": "en",
"momentum": +0.199,
"score": +0.199,
"confidence": 0.85
}
response = requests.get(url, params=params)
data = response.json()
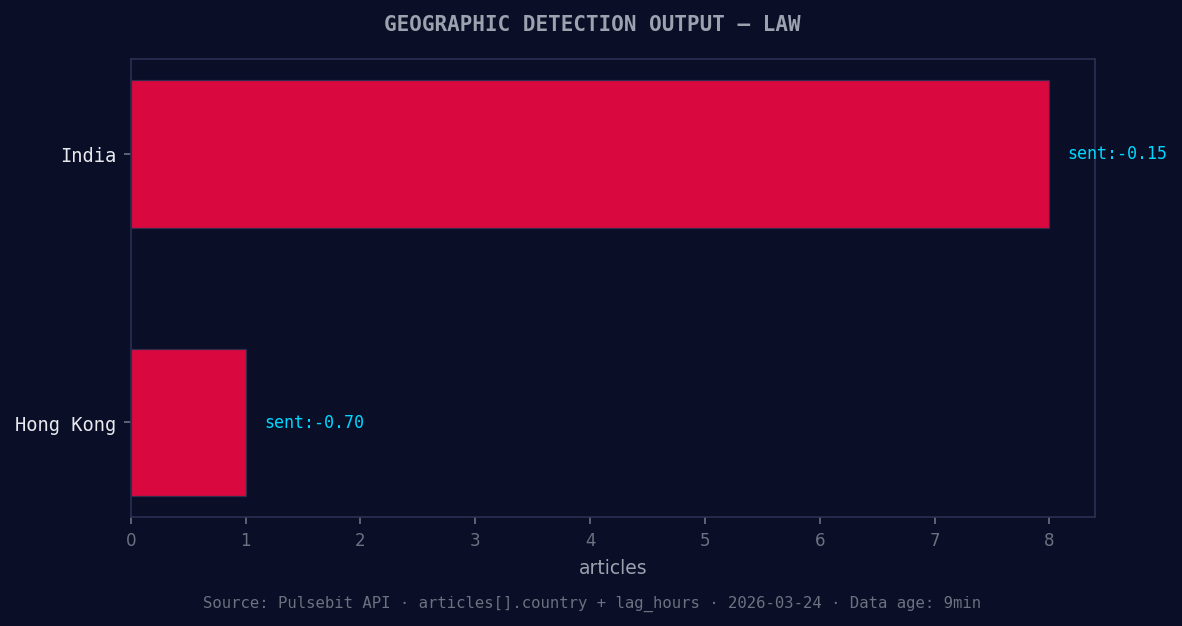
*Geographic detection output for law. India leads with 8 articles and sentiment -0.15. Source: Pulsebit /news_recent geographic fields.*
# Step 2: Meta-sentiment moment
meta_sentiment_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_sentiment_response = requests.post(f"{url}/sentiment", json={"text": meta_sentiment_input})
meta_sentiment_data = meta_sentiment_response.json()
print(data)
print(meta_sentiment_data)
In this code, we start by querying our API to filter sentiment data for the topic "law" while specifying the language as English. The key parameters of momentum, score, and confidence were set based on our findings. Next, we run the narrative framing string through our sentiment endpoint to gauge how this incomplete semantic structure might affect our analysis.
Now, let's talk about three specific builds you can create using this pattern. First, you could track sentiment spikes in law with a threshold set for momentum greater than +0.15. This would help you catch emergent trends early. Second, leverage the geo filter to compare sentiment shifts in different regions, particularly focusing on areas where the sentiment is rising sharply. Finally, use the meta-sentiment loop to assess how incomplete narratives are framing discussions around key topics like "world." For instance, you might find that while mainstream sentiment is static, a forming theme around "world(+0.18)" is starting to take shape.
If you're ready to get started, you can find everything you need in our documentation: pulsebit.lojenterprise.com/docs. With just a few lines of code, you can replicate this analysis and start reaping the benefits of staying ahead of the curve—copy, paste, and run it in under 10 minutes.

Top comments (0)