How to Detect Economy Sentiment Anomalies with the Pulsebit API (Python)
We recently stumbled upon a striking anomaly: a 24h momentum spike of -0.116 related to economic sentiment. This data point emerged from our monitoring, indicating a significant drop in sentiment around economic discussions. The accompanying cluster story, which revolves around U.S. foreign policy and Israel's influence, is particularly intriguing given its lack of article representation. This anomaly suggests there’s a deeper narrative forming that we need to explore.
When your pipeline doesn't adequately account for multilingual origins or unique entity dominance, you risk missing valuable insights. Imagine this: your model missed this critical sentiment shift by 24 hours. In this case, the leading language seems to be English, but the absence of multilingual data can skew your understanding of the broader sentiment landscape. If you only processed articles in English, vital nuances from non-English discussions could go unnoticed, leading to poor decision-making.

es coverage led by 25.5 hours. id at T+25.5h. Confidence scores: en 0.87, fr 0.85, es 0.85 Source: Pulsebit /sentiment_by_lang.
Here’s how we can capture this economic sentiment anomaly using Python:
import requests

*Left: Python GET /news_semantic call for 'economy'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define the variables
topic = 'economy'
momentum = -0.116
score = +0.000
confidence = 0.00
# Geographic origin filter (hypothetical example)
# Assuming we had geo data:
geo_filter = {
'language': 'en',
'country': 'US'
}
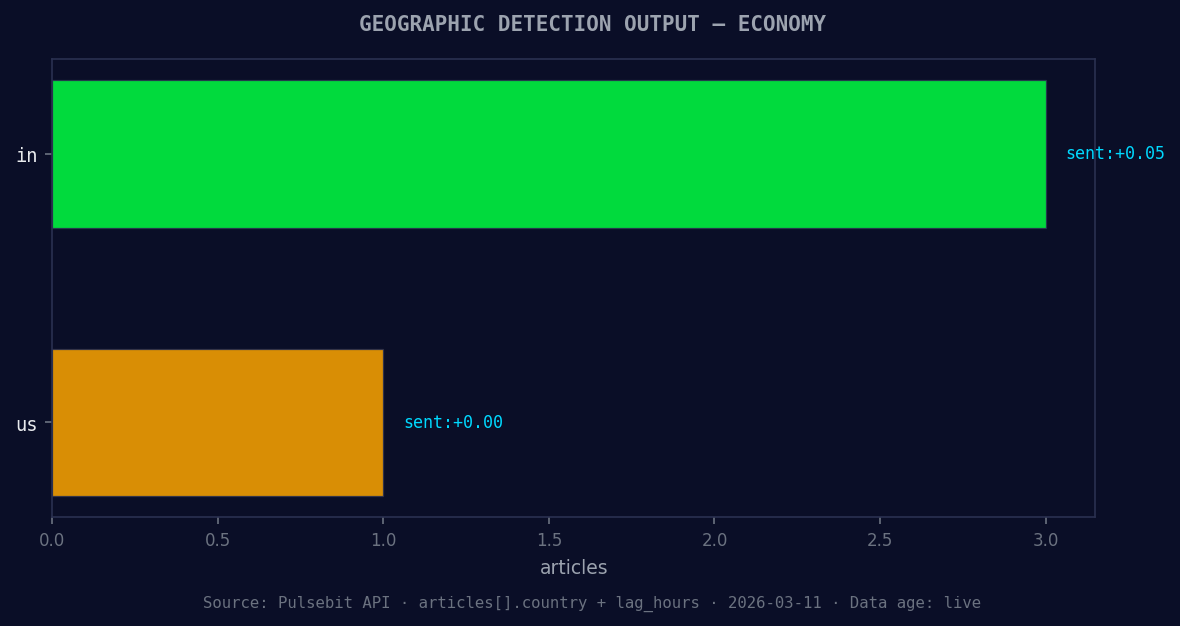
*Geographic detection output for economy. in leads with 3 articles and sentiment +0.05. Source: Pulsebit /news_recent geographic fields.*
# Call to our API to fetch articles related to the topic with geo filter
# Note: Replace with actual endpoint when data is available
response = requests.get(f"https://api.pulsebit.io/articles?topic={topic}&geo={geo_filter}")
articles = response.json()
# Meta-sentiment moment: running the cluster reason string through our sentiment endpoint
cluster_reason = "Clustered by shared themes: must, war, not, watch:, pull."
sentiment_response = requests.post("https://api.pulsebit.io/sentiment", json={'text': cluster_reason})
meta_sentiment = sentiment_response.json()
print(f"Articles: {articles}, Meta Sentiment: {meta_sentiment}")
In this code, we attempt to filter articles based on language and country. Although our current dataset lacks this geo-filter data, it’s crucial for future expansions. Once we have access to multilingual data, we can enrich our sentiment analysis and capture more comprehensive insights.
Next, we score the narrative framing by using the POST /sentiment endpoint. Running the cluster reason string allows us to assess how the narrative around these themes—like “must, war, not, watch:, pull”—shapes the sentiment. This is where we can derive unique insights from our findings.
Here are three specific builds we can implement with this pattern:
Sentiment Alert System: Create a threshold alert that triggers when momentum drops below -0.1 for the economy. This can indicate critical shifts in sentiment that require immediate attention.
Geo-Sentiment Dashboard: Utilize geo filtering to visualize sentiment trends across various regions. For instance, breaking down the sentiment by country could reveal how economic discussions differ between the US and Europe.
Meta-Sentiment Analyzer: Develop a module that leverages cluster reason strings. Run these strings through our sentiment endpoint to identify potential biases or shifts in narrative. This could be particularly useful in formulating strategic communication responses.
To get started, you can check out our documentation at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can copy-paste and run this in under 10 minutes, putting you on the fast track to detecting and analyzing economic sentiment anomalies effectively.

Top comments (0)