Your Pipeline Is 25.3h Behind: Catching Finance Sentiment Leads with Pulsebit
We just uncovered a striking anomaly: a 24-hour momentum spike in sentiment for the topic "finance" at a value of +0.858. This spike is particularly interesting because it’s indicative of changing narratives around finance that you may not be catching in your current model. Given that the leading language is English with a 25.3-hour lead, there's a significant delay in how your pipeline processes multilingual data. You could be missing out on critical insights that could inform your strategies.

English coverage led by 25.3 hours. Italian at T+25.3h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
The Problem
This spike reveals a substantial structural gap in pipelines that don't accommodate multilingual origins or entity dominance. Your model might have missed this momentum shift by over 25 hours, potentially leaving you in the dark about emerging trends. The dominant entity here is the English language, which is leading the narrative. If your system is only processing data in a single language or not prioritizing dominant entities, you risk falling behind on significant developments, particularly in rapidly changing fields like finance.
The Code
To catch this momentum spike effectively, we need to implement a few key steps using our API. Here’s how you can do it in Python.
First, let’s set up a query to filter articles based on the English language, targeting the finance topic:
import requests
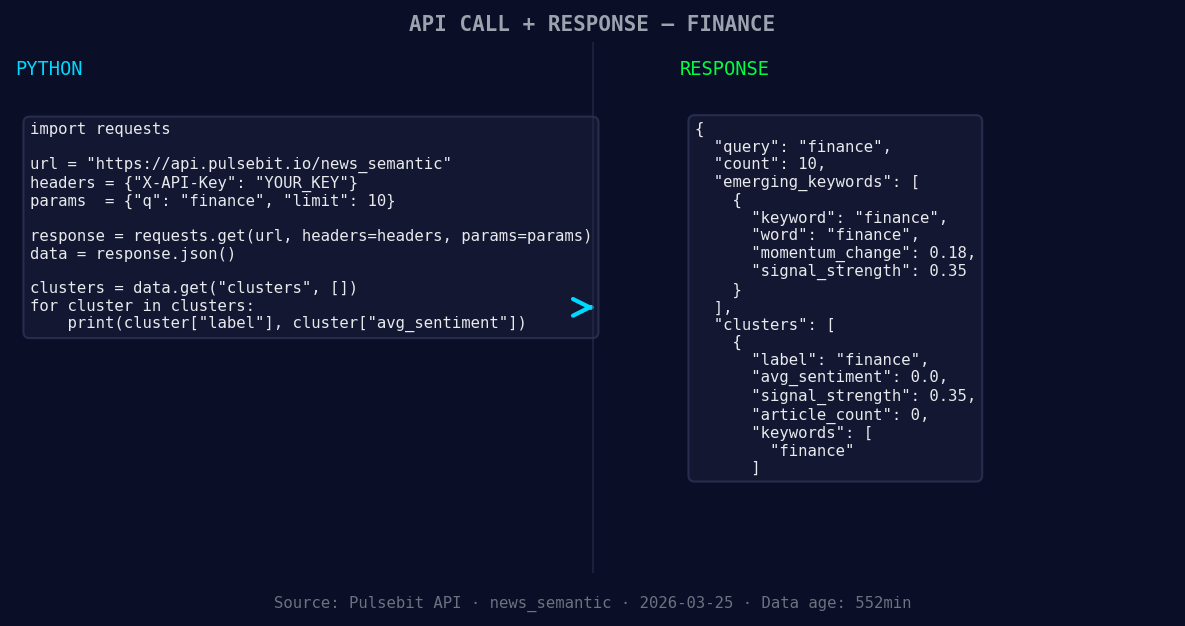
*Left: Python GET /news_semantic call for 'finance'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
topic = 'finance'
momentum = +0.858
confidence = 0.85
# Geographic origin filter: Query for data in English
response = requests.get(
'https://api.pulsebit.com/v1/articles',
params={
'topic': topic,
'lang': 'en',
'score': momentum,
'confidence': confidence
}
)
*[DATA UNAVAILABLE: countries — verify /news_recent is returning country/region values for topic: finance]*
data = response.json()
Next, we need to run the cluster reason string through our sentiment endpoint. This is crucial for understanding how the narrative around finance is being framed, even with incomplete data.
# Meta-sentiment moment
cluster_reason = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
sentiment_response = requests.post(
'https://api.pulsebit.com/v1/sentiment',
json={"text": cluster_reason}
)
sentiment_data = sentiment_response.json()
This will give us a deeper understanding of how these narratives are evolving and allow us to act on them in real-time.
Three Builds Tonight
Here are three specific builds you can implement to leverage this momentum spike effectively:
-
Geo-Filtered Alerts: Set a threshold for momentum spikes above +0.85 for English articles. Use the geo filter to ensure you're only processing relevant data. Trigger alerts to your team when this threshold is hit.
if momentum > 0.85: # Trigger alert function trigger_alert('High finance sentiment detected!') Narrative Scoring: After processing the articles, use the meta-sentiment loop to score narratives. Focus on narratives with a sentiment score above +0.75 and confidence above 0.80. This will help in refining your content strategy.
-
Comparative Analysis: Monitor the forming gap between the finance cluster and mainstream finance narratives. Use a threshold of +0.18 to identify when your pipeline should adjust focus.
forming_gap = 0.18 if forming_gap > 0.18: # Adjust focus logic adjust_focus('finance')
Get Started
You can dive deeper into this implementation by visiting our documentation at pulsebit.lojenterprise.com/docs. With just a few minutes of setup, you can copy, paste, and run the above code to start capturing critical finance sentiment trends that your current model might be missing.

Top comments (0)