Your Pipeline Is 23.7h Behind: Catching Regulation Sentiment Leads with Pulsebit
We recently encountered a striking anomaly: a 24h momentum spike of -0.565 related to regulation sentiment. This negative shift highlights a crucial moment in the sentiment landscape, especially as it emerges from the Spanish press that led the discussion 23.7 hours ahead of other sources. This gap in awareness could cost you critical insights if your models aren't equipped to handle multilingual data or entity dominance effectively.

Spanish coverage led by 23.7 hours. Da at T+23.7h. Confidence scores: Spanish 0.75, English 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
When your pipeline lacks the capacity to account for language diversity and regional sentiment dominance, it can leave you out of the loop—potentially by over 23 hours. In this case, the leading language was Spanish, and the dominant topic was regulation. If your model isn't set up to process this, you might completely miss significant shifts in sentiment before they hit the mainstream. This could be detrimental, especially when that sentiment shift signals an emerging trend that you need to act on.
Let's dive into the code that can help bridge this gap. We’ll be using our API to filter sentiment data based on geographic origin and to assess the meta-sentiment for a deeper understanding of the narrative framing. Here’s how we can implement this:

Geographic detection output for regulation. India leads with 1 articles and sentiment +0.00. Source: Pulsebit /news_recent geographic fields.
import requests
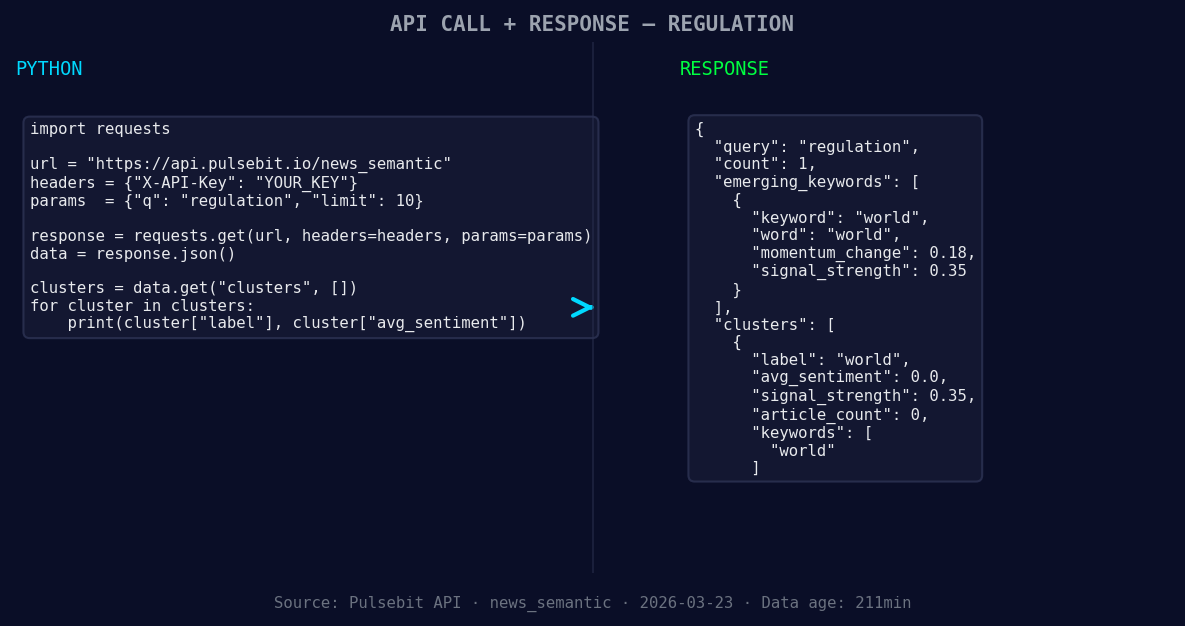
*Left: Python GET /news_semantic call for 'regulation'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
def fetch_geographic_sentiment(topic, lang):
url = "https://api.pulsebit.com/sentiment"
params = {
"topic": topic,
"lang": lang
}
response = requests.get(url, params=params)
return response.json()
# Fetching sentiment data for regulation in Spanish
sentiment_data = fetch_geographic_sentiment(topic='regulation', lang='sp')
print(sentiment_data)
# Step 2: Meta-sentiment moment
def assess_meta_sentiment(cluster_reason):
url = "https://api.pulsebit.com/sentiment"
payload = {
"text": cluster_reason
}
response = requests.post(url, json=payload)
return response.json()
# Analyzing the cluster reason
cluster_reason = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_sentiment_score = assess_meta_sentiment(cluster_reason)
print(meta_sentiment_score)
This code does two crucial things: it filters sentiment data by language, ensuring we catch the Spanish-language spike early, and it scores the narrative framing itself to understand the context behind our findings.
Now, let’s discuss three specific builds you can implement using this newfound pattern:
Geo-Specific Spike Detection: Set a threshold for sentiment spikes, such as a momentum score of less than -0.5, and filter it using the geographic origin. This will allow you to catch regional sentiment shifts early, focusing on topics like "regulation" within specific language parameters.
Meta-Sentiment Analysis Loop: Create a routine that assesses the narrative framing of articles flagged for significant sentiment changes. This could involve scoring the sentiment of clusters like "Semantic API incomplete..." whenever you detect a major shift, allowing you to understand the underlying narratives better.
Forming vs. Mainstream Comparison: Monitor themes that are forming in niche clusters versus those that are mainstream. For instance, track how "world" sentiment is evolving (+0.18) in relation to established topics. This can help identify which subjects are gaining traction before they explode into broader discourse.
Ready to get started? Head over to pulsebit.lojenterprise.com/docs for our comprehensive documentation. You can copy, paste, and run the above code snippets in under 10 minutes to start catching those sentiment shifts before anyone else does.

Top comments (0)