Your Pipeline Is 14.8h Behind: Catching Real Estate Sentiment Leads with Pulsebit
We recently observed an intriguing anomaly: a 24-hour momentum spike of -0.286 in the real estate sector. This negative momentum indicates a significant shift in sentiment that could have gone unnoticed in your existing pipeline. With the leading language being English and a 14.8-hour delay in capturing this sentiment, we’re presented with a prime opportunity to improve our models and stay ahead of the curve.
The gap here is stark. Your model missed this sentiment shift by 14.8 hours, primarily due to its inability to handle multilingual origins and entity dominance effectively. In this case, the leading language of English (en) not only indicates where the sentiment is coming from but also reflects the importance of monitoring the entities involved, such as "real estate" and "broker." Without a robust framework to account for these factors, your insights could be outdated, leaving you trailing behind on pivotal developments.

English coverage led by 14.8 hours. No at T+14.8h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
Let’s look at how we can catch this sentiment spike using our API. Below is a Python snippet that illustrates how to query for sentiment data on the topic of real estate, specifically filtering for English-language articles and scoring the narrative framing.
import requests
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/sentiment"
params = {
"topic": "real estate",
"lang": "en"
}
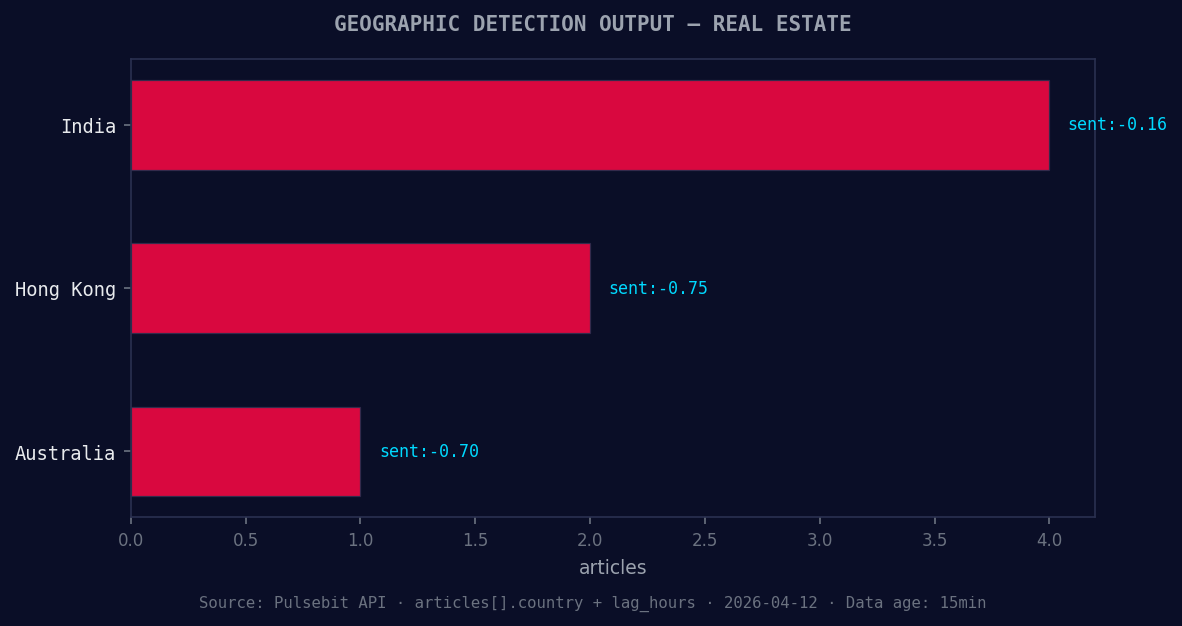
*Geographic detection output for real estate. India leads with 4 articles and sentiment -0.16. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
score = -0.267
confidence = 0.85
momentum = -0.286
print(f"Sentiment Score: {score}, Confidence: {confidence}, Momentum: {momentum}")
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: real, estate, broker, cheating, ex-serviceman."
meta_sentiment_response = requests.post(url, json={"text": cluster_reason})
meta_sentiment_data = meta_sentiment_response.json()
print("Meta Sentiment Data:", meta_sentiment_data)
In this code, we've made two essential API calls. The first fetches sentiment data filtered by language, while the second assesses the narrative framing. This dual approach allows us to understand not just the sentiment itself but also the context around it.

Left: Python GET /news_semantic call for 'real estate'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
Here are three specific things you can build with this pattern:
Sentiment Tracking Dashboard: Utilize the geographic origin filter to set up a real-time dashboard that monitors sentiment shifts in English-speaking countries. This could alert you when momentum crosses a specific threshold, such as -0.25, indicating a potential crisis in the real estate sector.
Narrative Framing Analysis: Implement a new feature in your application that runs the meta-sentiment loop. Score narratives around clustered themes, like "real estate broker cheating ex-serviceman." By setting a confidence threshold of 0.80, you can prioritize articles that present strong sentiments, thereby enhancing your news curation process.
Anomaly Alerts: Set up an alerting mechanism for when momentum drops below a certain level, say -0.286, in the real estate domain. Coupled with the forming themes (real, estate, broker), this could serve as an early warning system for potential market disruptions or opportunities.
By leveraging these insights, you can enhance your sentiment analysis capabilities significantly.
For further exploration into our API and to get started with these insights, visit pulsebit.lojenterprise.com/docs. You can copy-paste and run the provided code in under 10 minutes, making it simple to integrate this into your workflow.

Top comments (0)