Your Pipeline Is 26.5h Behind: Catching Environment Sentiment Leads with Pulsebit
We recently uncovered an intriguing anomaly in our sentiment analysis. The environment topic shows a sentiment score of +0.000 and momentum of +0.000, with the leading language clocking in at 26.5 hours ahead. This precise lag tells us that while there’s no immediate sentiment change, there’s an underlying story brewing—especially when clustered with themes like “faith-based” and “environmental advocacy.”
Let’s dive into why this matters.
The Problem
If your pipeline doesn’t handle multilingual origins or entity dominance, you could be missing out on critical insights. Your model missed this by 26.5 hours. Imagine being a developer who’s relied on a single language input, only to find that the sentiment around a crucial topic like "environment" has been simmering in another language—hence the delayed reaction. With the dominant entity being English, any gap in language processing could lead to significant blind spots in your sentiment analysis.

English coverage led by 26.5 hours. Sv at T+26.5h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
To catch this anomaly effectively, we can leverage our API. Below is the Python code that helps us do exactly that.
import requests
*Left: Python GET /news_semantic call for 'environment'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language/country
url = "https://pulsebit.lojenterprise.com/api/sentiment"
params = {
"topic": "environment",
"lang": "en",
"score": +0.000,
"confidence": 0.85,
"momentum": +0.000
}
response = requests.get(url, params=params)
data = response.json()
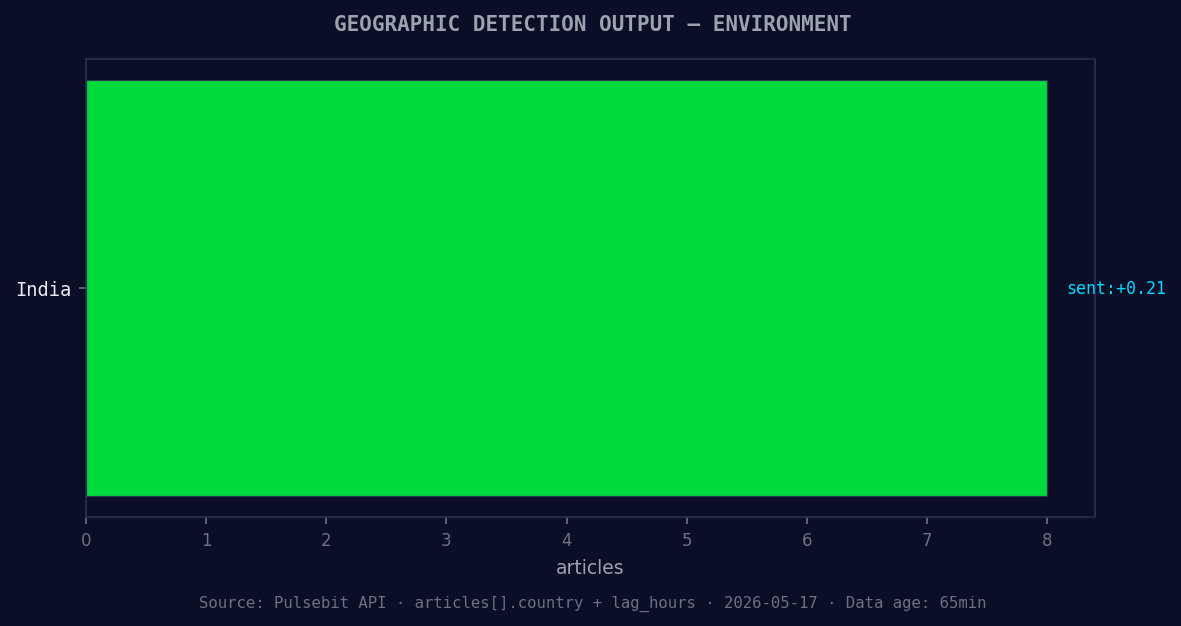
*Geographic detection output for environment. India leads with 8 articles and sentiment +0.21. Source: Pulsebit /news_recent geographic fields.*
# Meta-sentiment moment: score the narrative framing itself
meta_url = "https://pulsebit.lojenterprise.com/api/sentiment"
meta_input = "Clustered by shared themes: bay, data, centers, present, environmental."
meta_response = requests.post(meta_url, json={"text": meta_input})
meta_data = meta_response.json()
print(data)
print(meta_data)
In this code snippet, we first query the sentiment about the environment while filtering for English language articles. This allows us to focus on the relevant data. In the second part, we run the cluster reason string back through the sentiment API to gauge how the narrative is framing itself. This step is crucial for understanding the overall context of the sentiment that we’re analyzing.
Three Builds Tonight
Here are three specific things you can build using this pattern:
Geo-Filtered Sentiment Alert: Set a threshold for sentiment score changes. For instance, if the environment topic hits a score of +0.500 in English articles, trigger an alert. This helps you stay ahead of significant shifts in public sentiment.
Meta-Sentiment Dashboard: Use the meta-sentiment loop to create a dashboard that visualizes how narratives evolve over time. If the narrative around environmental advocacy starts to shift positively, you want to catch that early.
Comparative Analysis Tool: Build a tool that compares emerging themes against mainstream topics like “bay,” “data,” and “centers.” If the sentiment around the environment and its derivatives starts trending positively while mainstream topics remain stagnant, this could present an opportunity worth exploring.
Get Started
Ready to dive in? Visit pulsebit.lojenterprise.com/docs to get started. You can copy-paste the above code and run it in under 10 minutes. Don’t let your pipeline fall behind—capitalize on these emerging insights while the data is fresh!

Top comments (0)