Your Pipeline Is 24.8h Behind: Catching Artificial Intelligence Sentiment Leads with Pulsebit
We just spotted a notable anomaly: a 24h momentum spike of +0.547 centered around the topic of artificial intelligence. This is a significant uptick, especially in the context of the recent news article titled, "US sounds alarm over China’s humanoid robots amid security concerns." The leading language for this spike? Spanish, with a 24.8-hour lag, indicating an overlooked narrative that could have given us valuable insights into emerging technological concerns.
However, if your model isn't equipped to handle multilingual data or recognize entity dominance, you might have missed this critical development by a staggering 24.8 hours. This gap can put you behind competitors who are already capitalizing on these emerging trends. In this case, the dominant entity is China, and the leading language is Spanish. If your pipeline only focuses on English, you’re not just lagging; you are at risk of missing entire conversations that shape sentiment around crucial topics like artificial intelligence.

Spanish coverage led by 24.8 hours. Et at T+24.8h. Confidence scores: Spanish 0.85, English 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly and stay ahead, we can leverage our API to filter and analyze the data. Here’s how to do it with Python:
import requests
# Set up parameters for the API call
topic = 'artificial intelligence'
score = +0.000
confidence = 0.85
momentum = +0.547
lang = 'es' # Spanish language filter
*Left: Python GET /news_semantic call for 'artificial intelligence'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: Query the API for Spanish language articles
response = requests.get(
f"https://pulsebit.api/v1/articles?topic={topic}&lang={lang}"
)
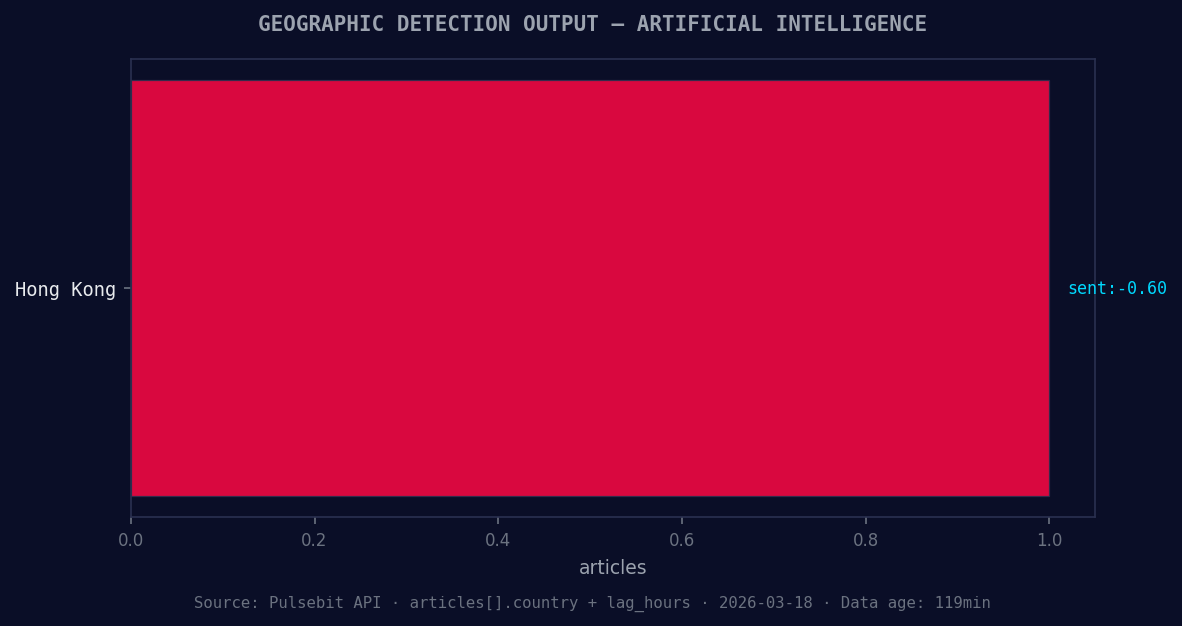
*Geographic detection output for artificial intelligence. Hong Kong leads with 1 articles and sentiment -0.60. Source: Pulsebit /news_recent geographic fields.*
# Print the response to see the articles
print(response.json())
Next, we take the cluster reason string and score its narrative framing using another endpoint. This step is crucial because it allows us to assess the sentiment behind the themes being discussed:
# Meta-sentiment moment: Score the narrative framing itself
cluster_reason = "Clustered by shared themes: humanoid, robots, china’s, security, robotics."
sentiment_response = requests.post(
"https://pulsebit.api/v1/sentiment",
json={"text": cluster_reason}
)
# Output the sentiment score and confidence
print(sentiment_response.json())
With these two pieces of code, we’re not just reacting to trends; we’re actively shaping our understanding of them.
Now that we have a method for capturing these spikes, here are three specific builds you can implement tonight:
Geo-Focused Alert System: Set a signal threshold for artificial intelligence-related topics with a momentum spike above +0.5. Use the Spanish language filter to notify your team when the sentiment shifts, allowing you to stay ahead of the curve.
Meta-Sentiment Dashboard: Create a dashboard that visualizes the sentiment scores of cluster reasons like "humanoid, robots, China’s, security, robotics." This will help you quickly identify which narratives are gaining traction and deserve more attention.
Automated Reporting: Write a script that generates daily reports highlighting emerging themes in artificial intelligence. Utilize both the geo filter and the sentiment loop to capture new vs mainstream discussions around pivotal issues like humanoid robotics and security concerns.
By implementing these builds, you can harness the momentum of emerging topics and ensure your analytics are timely and relevant.
Want to start building these insights? Check out our documentation at pulsebit.lojenterprise.com/docs. You can copy, paste, and run this code in under 10 minutes to catch your own momentum spikes.

Top comments (0)