Your Pipeline Is 24.8h Behind: Catching Cloud Sentiment Leads with Pulsebit
We just stumbled upon a fascinating anomaly: a 24h momentum spike of +0.595 in sentiment surrounding the topic of cloud. This significant increase, observed in English press coverage, begs a closer look into how we can leverage this insight. The implications of this spike are underscored by the fact that the leading language for this data is English, lagging behind Italian press by 24.8 hours.
The Problem
This scenario reveals a critical structural gap in any data pipeline that doesn't account for multilingual content and entity dominance. Your model missed this by 24.8 hours. If you’re relying solely on one language or a single source of information, you’re missing out on actionable insights. For instance, while English press coverage is catching up, the Italian press was already ahead, meaning you could have acted on this information significantly earlier.

English coverage led by 24.8 hours. Italian at T+24.8h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
To catch this momentum spike effectively, we can use our API to filter the relevant data. Here’s how we can implement it in Python:
import requests
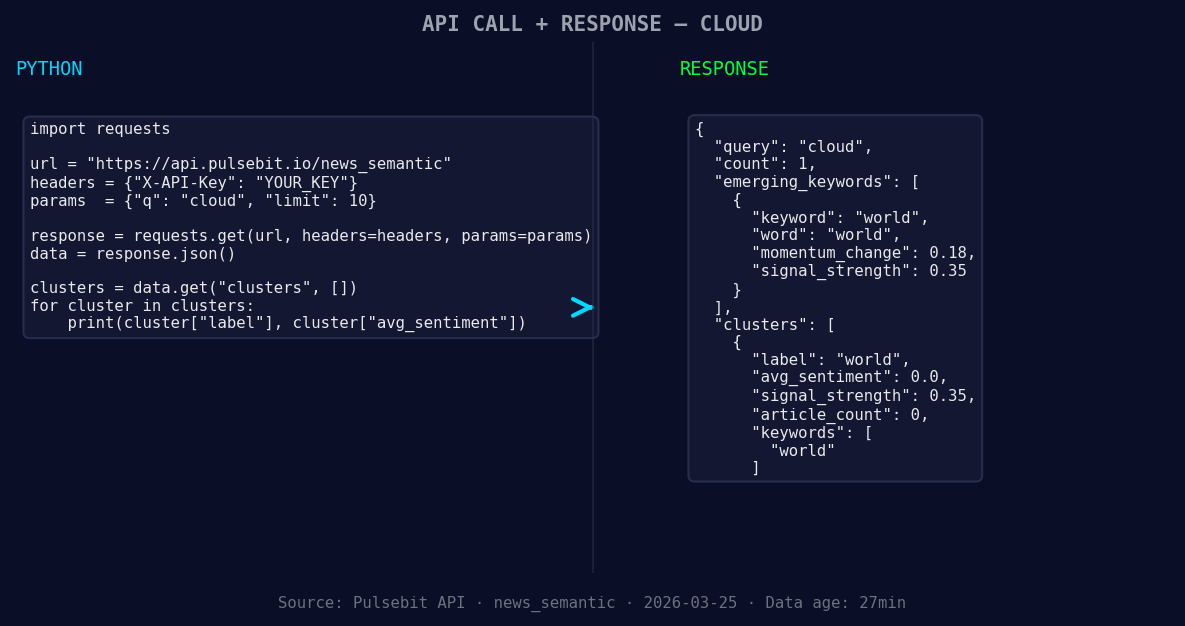
*Left: Python GET /news_semantic call for 'cloud'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Define the parameters
topic = 'cloud'
score = +0.595
confidence = 0.85
momentum = +0.595
# Geographic origin filter: query by language/country
response = requests.get("https://api.pulsebit.com/v1/articles", params={
"topic": topic,
"lang": "en",
"momentum": momentum
})
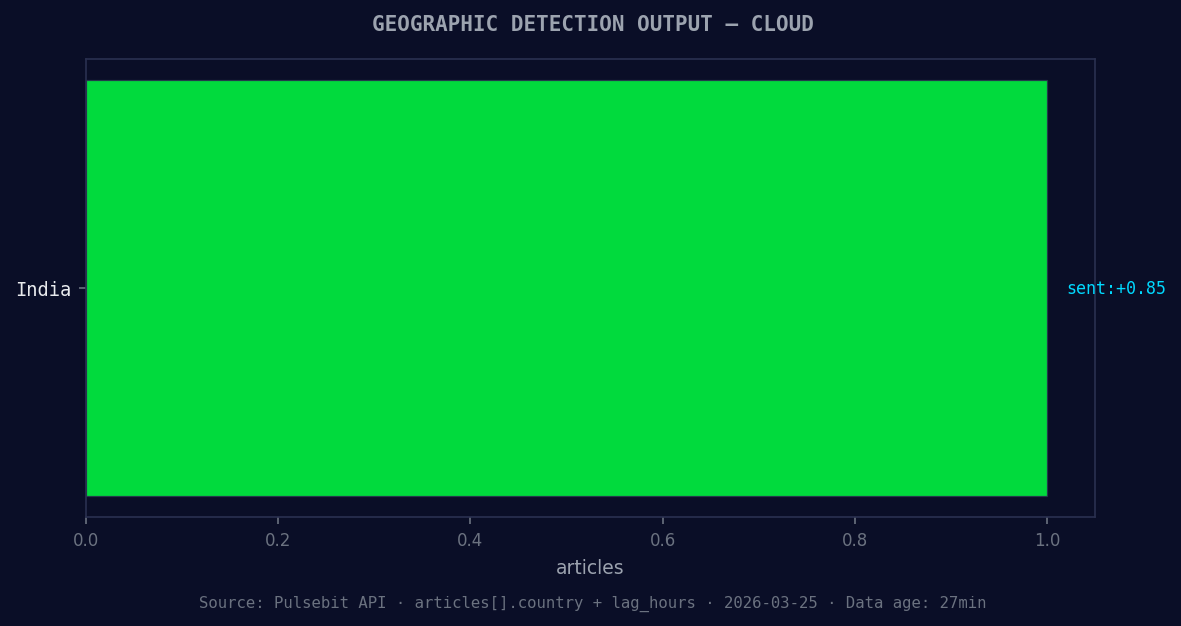
*Geographic detection output for cloud. India leads with 1 articles and sentiment +0.85. Source: Pulsebit /news_recent geographic fields.*
# Check response
if response.status_code == 200:
articles = response.json()
print("Articles Retrieved: ", articles)
else:
print("Error fetching articles: ", response.status_code)
# Meta-sentiment moment: scoring the narrative framing
narrative = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
sentiment_response = requests.post("https://api.pulsebit.com/v1/sentiment", json={
"text": narrative
})
# Check sentiment response
if sentiment_response.status_code == 200:
sentiment_score = sentiment_response.json()
print("Sentiment Score: ", sentiment_score)
else:
print("Error fetching sentiment score: ", sentiment_response.status_code)
In this code, we first filter articles related to the topic "cloud" and check for those in English. We then send the fallback narrative to our sentiment endpoint to score the context around this anomaly. This two-step approach allows us to not only catch trending sentiment but also understand the framing of the narrative itself.
Three Builds Tonight
Here are three specific things you can build using this pattern:
Geo Filtered Alerts: Create an alert system that triggers whenever there’s a momentum spike above a specific threshold (e.g., +0.5) for a given topic in English. Use the geographic origin filter to ensure that you’re capturing real-time insights.
Meta-Sentiment Dashboard: Build a dashboard that visualizes meta-sentiment scores around narratives that have been identified as incomplete. For example, track narratives around "world" that are forming (+0.18 vs mainstream) and compare them to the average sentiment across various topics.
Anomaly Detection System: Implement an anomaly detection system that flags any sentiment spikes greater than +0.5 and correlates them with article volume. This will help you spot trends faster, especially in competitive fields like "cloud" where information can change rapidly.
Get Started
To dive deeper into building these features, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run the provided code in under 10 minutes, and start catching those sentiment leads before your competitors do.

Top comments (0)