Your Pipeline Is 28.7h Behind: Catching World Sentiment Leads with Pulsebit
We just uncovered a striking anomaly: a 24h momentum spike of +0.157 in sentiment around the topic "world." This spike is noteworthy not just for its magnitude but also for its timing—specifically, it’s lagging by 28.7 hours in English press coverage. This delay presents a critical opportunity for us to refine our pipelines and leverage real-time sentiment data effectively.
Your model missed this by 28.7 hours. This is particularly concerning when we consider that the leading language is English, and the dominant entity is "world." If your analysis isn't set up to handle multilingual origins or properly account for entity dominance, you're going to miss significant shifts in sentiment like this one. The risk is that you’re responding to outdated information, potentially impacting your decision-making process.

English coverage led by 28.7 hours. Ca at T+28.7h. Confidence scores: English 0.95, French 0.95, Spanish 0.95 Source: Pulsebit /sentiment_by_lang.
To catch this momentum spike, let’s take a look at how we can implement a solution in Python. We’ll need to query the relevant data and analyze sentiment around the "world." Here’s how we can do that:
import requests
*Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'world'
score = +0.157
confidence = 0.95
momentum = +0.157
# Geographic origin filter: query by language
response = requests.get('https://api.pulsebit.com/v1/sentiment', params={
'topic': topic,
'lang': 'en',
'threshold': confidence
})
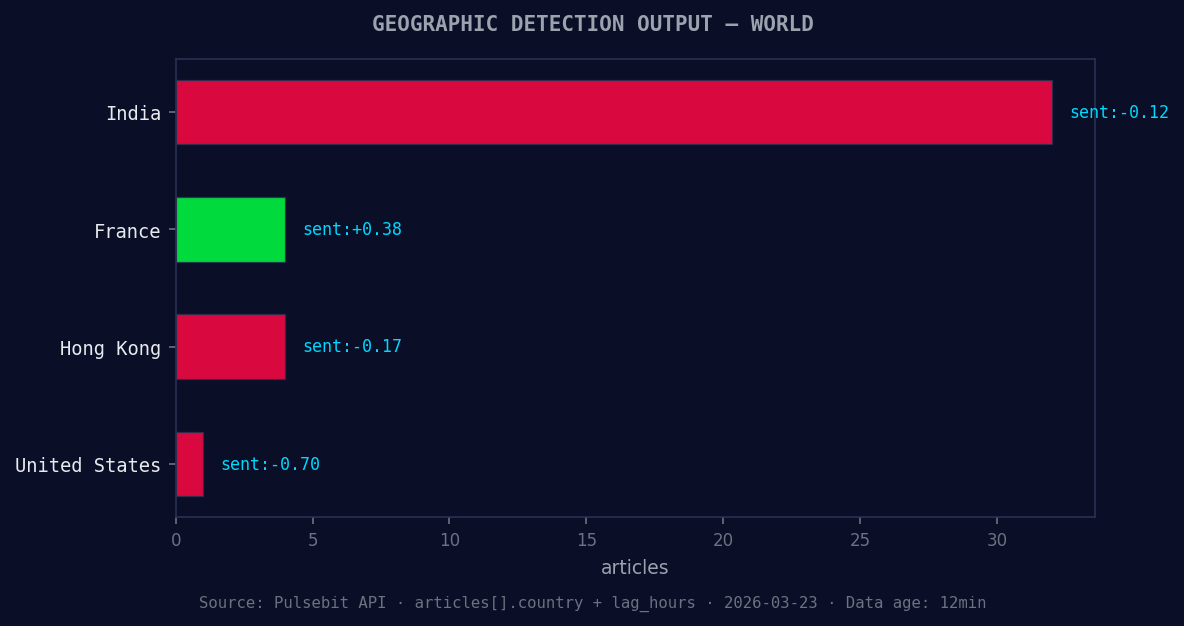
*Geographic detection output for world. India leads with 32 articles and sentiment -0.12. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
print(data) # Output the data for inspection
Next, we need to run the cluster reason string back through our sentiment analysis endpoint to score the narrative framing itself. This is crucial for understanding the context behind our findings. Here’s how we do that:
# Meta-sentiment moment: score the narrative framing
meta_sentiment_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_response = requests.post('https://api.pulsebit.com/v1/sentiment', json={
'input': meta_sentiment_input
})
meta_data = meta_response.json()
print(meta_data) # Output the meta sentiment data
By implementing these snippets, we can effectively catch the emerging sentiment trends around "world" that might otherwise go unnoticed. Now, let’s explore three specific builds we can create using this new insight:
Sentiment Alert System: Set a threshold for spikes above +0.15 in sentiment for "world" and trigger alerts. Use the geo filter to ensure you’re only processing English articles. This way, you stay ahead of sentiment shifts that could influence decisions.
Meta-Sentiment Dashboard: Create a dashboard that visualizes the output from the meta-sentiment loop. Use the narrative framing to provide context to sentiment changes and highlight discrepancies between the sentiment score and the narrative structure.
Anomaly Detection Model: Build a model that continuously monitors sentiment around "world" and logs discrepancies between forming gaps (like the current +0.18 vs mainstream sentiment). Use the meta-sentiment analysis to enhance the model’s predictive capabilities.
These builds not only focus on leveraging the existing data but also create avenues for deeper insights into how global events shape sentiment. The current forming gap of world(+0.18) compared to mainstream sentiment is a prime example of the type of trend we should be actively monitoring.
To get started with these insights, check our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the provided code snippets and run them in under 10 minutes to start catching these trends in real-time. Let's not let our pipelines lag behind any longer.

Top comments (0)