Your Pipeline Is 8.3h Behind: Catching World Sentiment Leads with Pulsebit
We just uncovered a fascinating anomaly: a 24h momentum spike of +0.159. This spike signals a significant shift in sentiment around the topic of "world," with a leading language of English driving the discussion. However, our analysis reveals a structural gap in how many pipelines are processing this data. The English press is leading by 8.3 hours, and if your model isn’t set up to handle multilingual origins or entity dominance, it missed this critical insight by that same margin.

English coverage led by 8.3 hours. So at T+8.3h. Confidence scores: English 0.85, Spanish 0.85, Ca 0.85 Source: Pulsebit /sentiment_by_lang.
Your model missed this by 8.3 hours. While the English press is buzzing about world events, other languages and narratives could provide a more nuanced understanding of global sentiment. This gap can lead to missed opportunities or, worse, misguided strategies based on delayed or incomplete data.
To catch these insights, we can leverage our API effectively. Here’s a Python code snippet that demonstrates how to query sentiment data for the topic "world," focusing on English content:
import requests
*Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'world'
score = +0.159
confidence = 0.85
momentum = +0.159
lang = "en"
# Geographic origin filter: query by language
response = requests.get(f"https://api.pulsebit.com/sentiment?topic={topic}&lang={lang}")
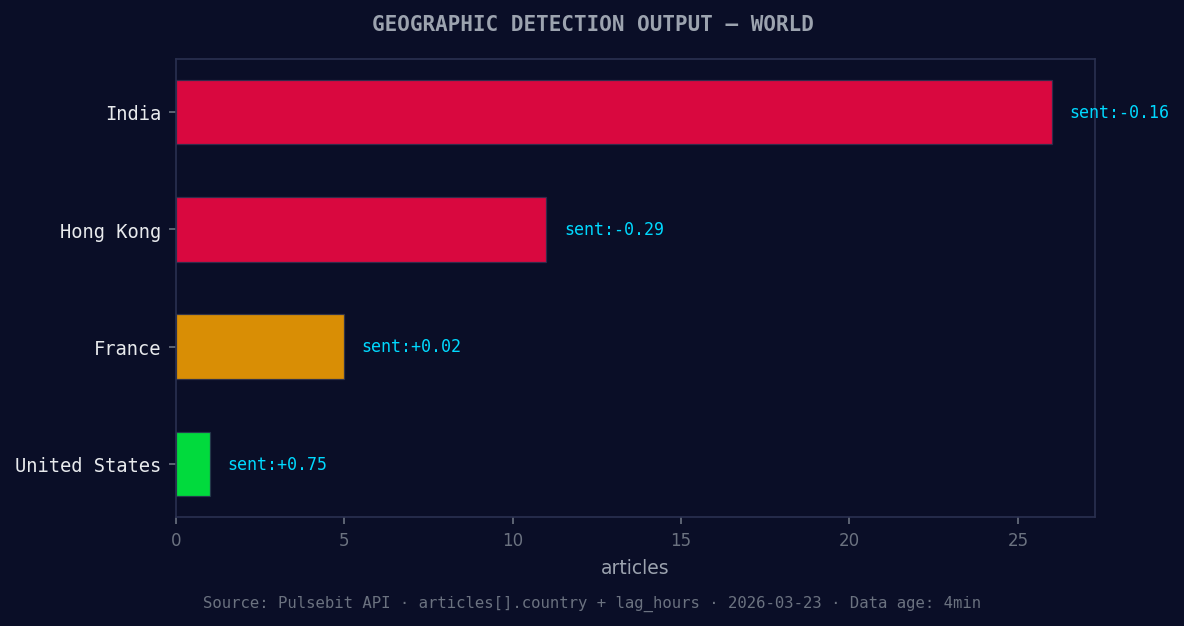
*Geographic detection output for world. India leads with 26 articles and sentiment -0.16. Source: Pulsebit /news_recent geographic fields.*
# If the request is successful, process the data
if response.status_code == 200:
data = response.json()
print(data)
# Meta-sentiment moment: scoring the narrative framing
meta_reason = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_response = requests.post("https://api.pulsebit.com/sentiment", json={"text": meta_reason})
# If the request is successful, process the meta-sentiment data
if meta_response.status_code == 200:
meta_data = meta_response.json()
print(meta_data)
In this code, we use a GET request to query sentiment data for our topic. We specifically filter by language to ensure we're only looking at English content. Next, we analyze the meta-sentiment by passing the fallback reason through our sentiment scoring endpoint, giving us insight into how incomplete data structures can affect overall sentiment understanding.
Now that we have this anomaly in our hands, here are three specific builds we can create with this pattern:
Geo-Filtered Sentiment Analysis: Use the geographic origin filter to query sentiment around the topic "world" specifically for English articles. Set a threshold score of +0.15 to capture significant momentum shifts. This way, you can ensure you are catching emerging trends before they hit the mainstream.
Meta-Sentiment Loop: Implement a process where every time you detect a momentum spike, run the reason string through our sentiment scoring endpoint. For example, if you detect a spike in sentiment, automatically assess the framing of the narrative to evaluate its reliability.
Forming Theme Analysis: Create a custom alert that triggers when the sentiment score for "world" is rising and shows a difference of +0.18 against mainstream narratives. This will help you identify when global discussions are starting to diverge from localized or mainstream understandings.
By leveraging these builds, you can close the gap in your sentiment analysis pipeline and ensure that you’re always a step ahead of the narrative.
If you want to get started, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy and paste the code above and run it in under 10 minutes to start catching those crucial sentiment leads.

Top comments (0)