Your Pipeline Is 27.9h Behind: Catching Tech Sentiment Leads with Pulsebit
We just stumbled upon an intriguing anomaly: a 24-hour momentum spike of -0.850 in the tech sector. This finding, rooted in a recent analysis, highlights a significant shift in sentiment, particularly emphasized by our leading language metric, which is English with a 27.9-hour lead time. This lag indicates that if you’re not tapping into multilingual content or understanding the dominance of certain entities, you could be missing critical sentiment shifts by nearly 28 hours.

English coverage led by 27.9 hours. Sv at T+27.9h. Confidence scores: English 0.75, Spanish 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
The structural gap this discovery reveals is critical. Your model missed this by a staggering 27.9 hours, indicating that you’re not fully leveraging the breadth of sentiment data. The leading language is English, meaning you might be too focused on mainstream narratives around coding and tech projects. If your pipeline isn't handling multilingual sources or entity dominance, you're likely falling behind in capturing emerging trends.
To catch up, we can use our API to pinpoint this sentiment shift effectively. Here’s how you can do it:
import requests
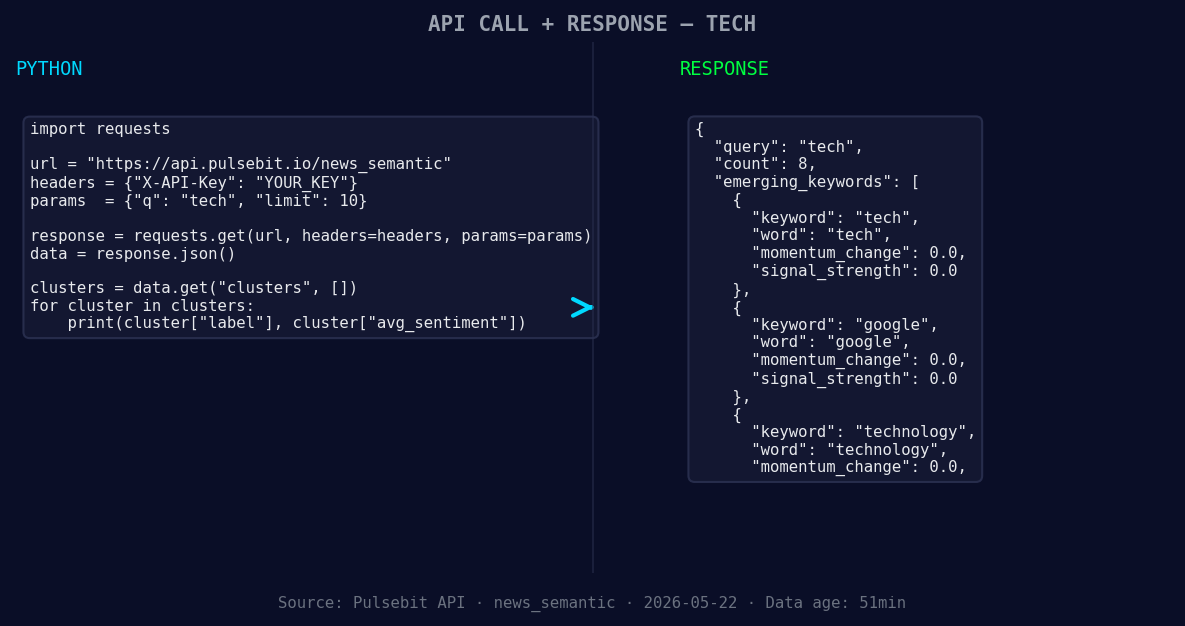
*Left: Python GET /news_semantic call for 'tech'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define the parameters for our query
topic = 'tech'
score = +0.430
confidence = 0.75
momentum = -0.850
# Geographic origin filter: querying by language
response = requests.get(
'https://api.pulsebit.com/v1/sentiment',
params={
'topic': topic,
'score': score,
'confidence': confidence,
'momentum': momentum,
'lang': 'en'
}
)
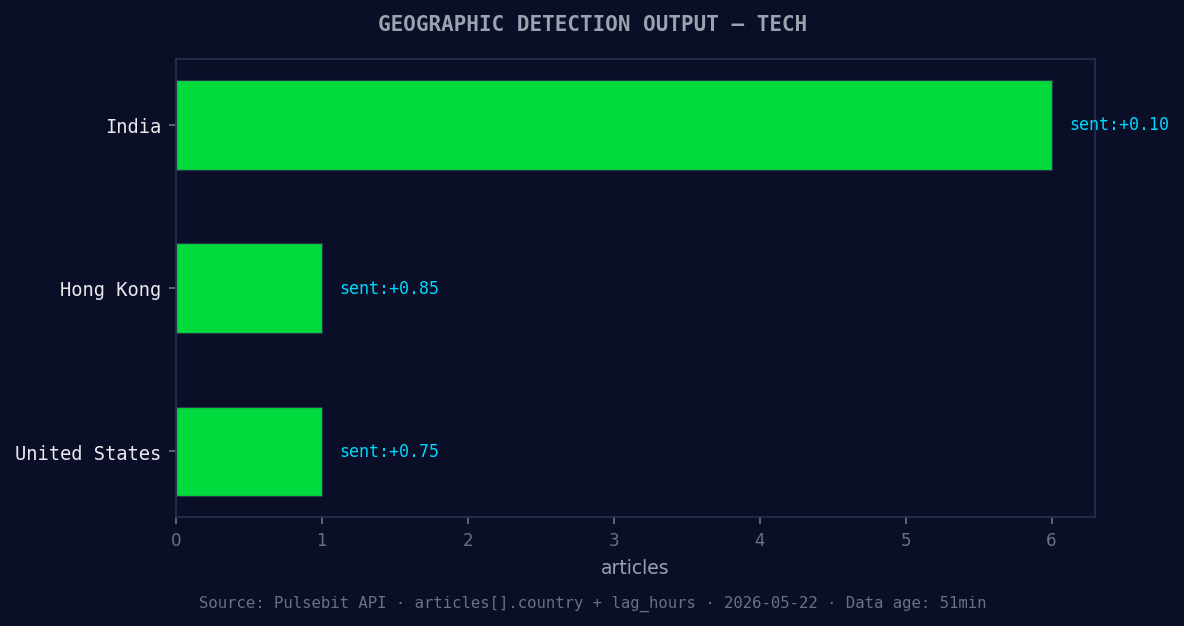
*Geographic detection output for tech. India leads with 6 articles and sentiment +0.10. Source: Pulsebit /news_recent geographic fields.*
# Print the response to see the filtered results
print(response.json())
Next, we need to analyze the narrative framing itself. Using our cluster reason string, we can post it to the /sentiment endpoint to get a score on how this framing influences overall sentiment:
# Meta-sentiment moment: running the cluster reason string back through POST /sentiment
cluster_reason = "Clustered by shared themes: coding, projects, tech, education, why."
meta_response = requests.post(
'https://api.pulsebit.com/v1/sentiment',
json={'text': cluster_reason}
)
# Print the sentiment score for the meta analysis
print(meta_response.json())
With these insights, we can build some targeted signals based on this pattern. Here are three specific builds to consider:
Geographic Sentiment Signal: Set a threshold for tech sentiment score above +0.400 using the geo filter. This will help you detect emerging trends in English-speaking regions.
Meta-Sentiment Analysis: Create a signal that triggers when the meta-sentiment score for cluster reasons is above +0.500. This helps you gauge the effectiveness of narrative framing around tech projects.
Forming Gap Alert: Establish a threshold that alerts you when the forming gap around keywords like "tech", "google", and "technology" compared to mainstream narratives around "coding" and "projects" shows a significant divergence. This could be set at a difference of more than +0.200.
By implementing these builds, you'll be better equipped to catch sentiment leads in the tech sector, ensuring you're not left behind as trends unfold.
Ready to get started? Head over to pulsebit.lojenterprise.com/docs and copy-paste the code above. You can run this in under 10 minutes and start harnessing these insights for your projects today.

Top comments (0)