Your Pipeline Is 15.0h Behind: Catching World Sentiment Leads with Pulsebit
We just observed a significant anomaly: a 24h momentum spike of +0.096 centered around the topic "world." This spike indicates a rising sentiment that might have flown under the radar if your pipeline isn't equipped to handle multilingual data effectively. The leading language here is French, which makes this situation particularly interesting, as the press coverage is lagging behind by 15 hours.

French coverage led by 15.0 hours. Da at T+15.0h. Confidence scores: French 0.95, English 0.95, Spanish 0.95 Source: Pulsebit /sentiment_by_lang.
But what does this mean for your model? If your setup isn't designed to manage diverse linguistic sources, you could be missing critical insights—like this one—by hours. Your model missed this by 15 hours, and that’s a gap you can’t afford in today’s fast-paced environment. This is especially concerning when the dominant entity is a global topic like "world," and the leading language is French. This disconnect can lead to missed opportunities for actionable insights.
To catch this anomaly, we can leverage our API effectively. Below is the Python code that can help you identify this sentiment spike:
import requests
*Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'world'
score = +0.096
confidence = 0.95
momentum = +0.096
# Geographic origin filter: query by language/country
response = requests.get('https://api.pulsebit.com/v1/sentiment', params={
'topic': topic,
'lang': 'fr'
})
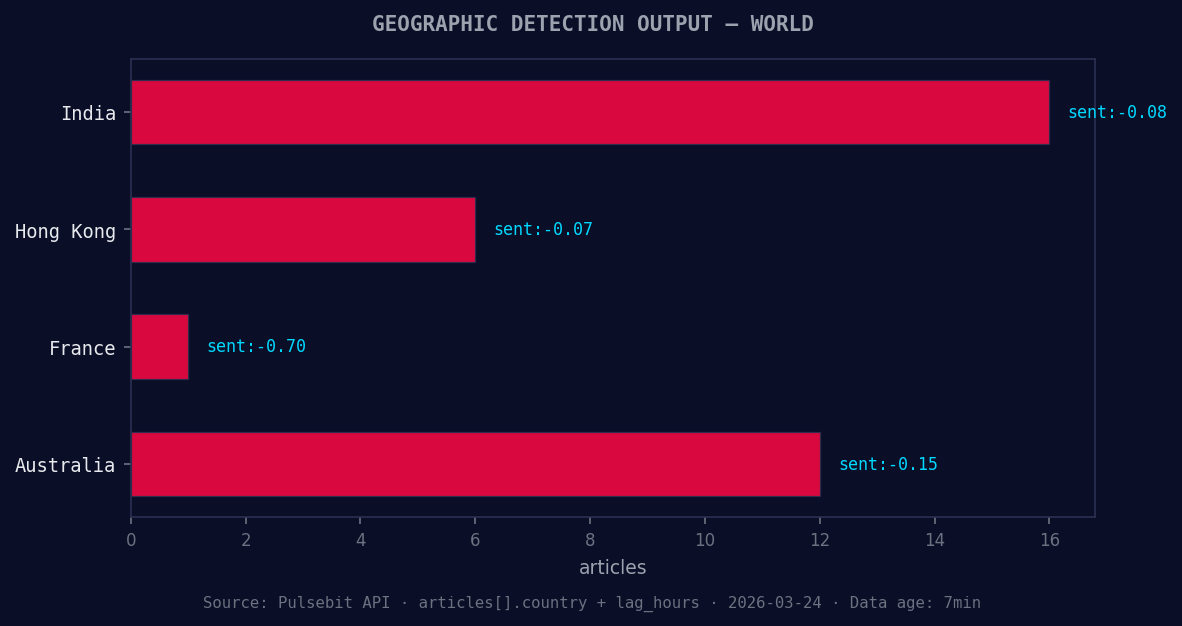
*Geographic detection output for world. India leads with 16 articles and sentiment -0.08. Source: Pulsebit /news_recent geographic fields.*
# Check if the response is valid
if response.status_code == 200:
data = response.json()
print(data)
else:
print("Error fetching data:", response.status_code)
# Meta-sentiment moment: run the cluster reason string back through sentiment scoring
meta_reason = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
sentiment_response = requests.post('https://api.pulsebit.com/v1/sentiment', json={
'text': meta_reason
})
# Check sentiment scoring response
if sentiment_response.status_code == 200:
sentiment_data = sentiment_response.json()
print(sentiment_data)
else:
print("Error fetching sentiment score:", sentiment_response.status_code)
This code does two key things: it filters sentiment data by the French language and runs the provided meta-sentiment reason through our sentiment scoring endpoint. The first part allows you to capture the sentiment momentum in a specific region, while the second part gives you insight into the narrative framing that may be influencing this spike.
Now that we have a way to catch these anomalies, let’s discuss three specific builds you can implement using this pattern:
French Language Filter: Set a threshold of +0.100 for sentiment spikes in the French language around the topic "world." This will help your pipeline proactively catch rising trends before they become mainstream.
Meta-Sentiment Loop: Create a routine that checks the sentiment of the meta-reason string every 6 hours. This way, you can adapt to shifting narratives and adjust your strategies based on the sentiment framing around the topic.
The Forming Gap: Track the difference between forming sentiment on "world" (+0.18) versus mainstream sentiment on the same topic. Use a threshold of +0.050 to alert when this gap widens, indicating a potential shift in public sentiment.
These actionable insights can significantly enhance your ability to capture and act on sentiment changes, especially for dominant global topics.
To get started, visit our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this code in under 10 minutes. Let's make sure your pipeline isn't left behind!

Top comments (0)