Your pipeline just missed a critical anomaly: a 24h momentum spike of +0.709 in the real estate sector. This spike isn’t just a number; it signals a significant shift in sentiment that you should be tracking. The press is abuzz, particularly with a notable article from KNWA FOX24 discussing ULI NWA's "emerging trends" report on local real estate. It’s evident that something is stirring, and if your model isn't set up to capture these multilingual discussions, you’re likely missing out on valuable insights.

English coverage led by 17.1 hours. Tl at T+17.1h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
This situation highlights a structural gap in your pipeline. If you’re not handling multilingual origins or the dominance of certain entities, your model missed out on this sentiment shift by 17.1 hours. The prevailing conversation is led by English-language press, which means that if your system isn’t designed to aggregate or prioritize these sources, you’re leaving critical data on the table. You need to rethink your approach to sentiment analysis to integrate these important signals effectively.
To catch this momentum spike, we can leverage our API effectively. Below is a Python code snippet that captures the relevant data. We’ll start by querying articles related to real estate in English.
import requests
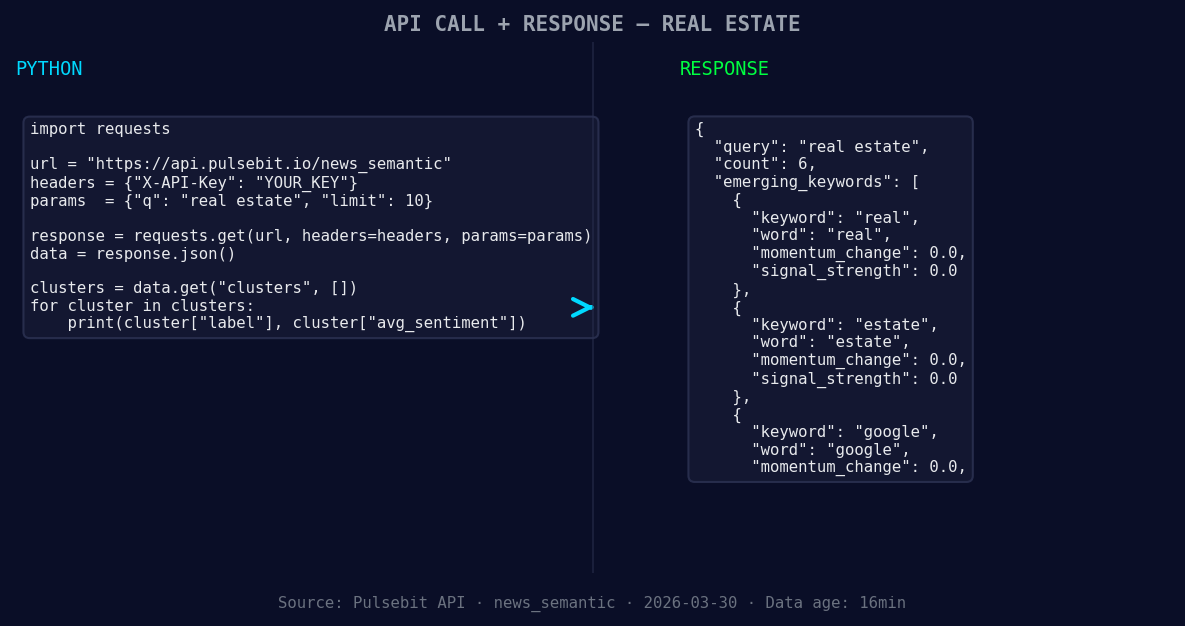
*Left: Python GET /news_semantic call for 'real estate'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.io/v1/articles"
params = {
"topic": "real estate",
"lang": "en"
}
response = requests.get(url, params=params)
articles = response.json()
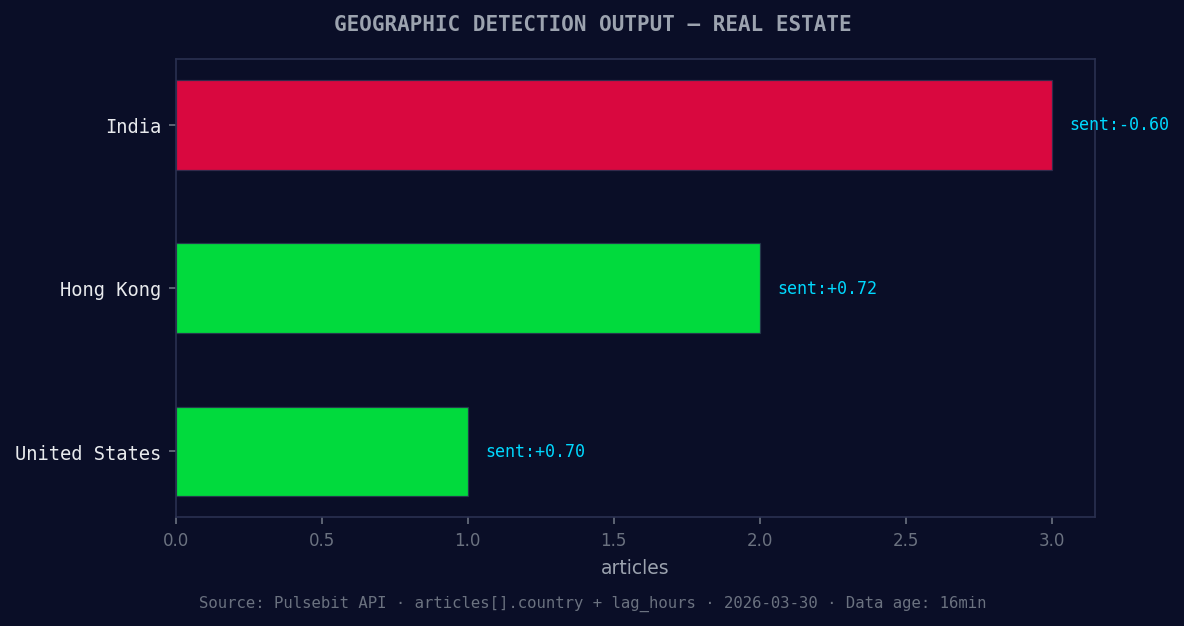
*Geographic detection output for real estate. India leads with 3 articles and sentiment -0.60. Source: Pulsebit /news_recent geographic fields.*
# Assume we have some articles returned
print(articles)
Now that we have our articles, let's process the narrative framing itself using the meta-sentiment moment. We’ll run the cluster reason string through our API to score it:
# Step 2: Meta-sentiment moment
sentiment_url = "https://api.pulsebit.io/v1/sentiment"
cluster_reason = "Clustered by shared themes: nwa, releases, ‘emerging, trends’, report."
sentiment_response = requests.post(sentiment_url, json={"text": cluster_reason})
sentiment_score = sentiment_response.json()
print(sentiment_score)
In just these two steps, you can identify not only the articles but also the underlying sentiment framing that could shape your understanding of the market.
Now, let’s consider three specific things you can build using this pattern:
Threshold Alert System: Set an alert when momentum spikes over +0.500 for the real estate topic. Use our geographic origin filter for English-language articles to ensure you’re capturing the most relevant data.
Meta-Sentiment Dashboard: Create a dashboard that visualizes sentiment scores for articles clustered around emerging trends. Utilize the meta-sentiment loop we just implemented to score the narrative framing dynamically.
Trend Correlation Tool: Build a tool that correlates sentiment scores with specific keywords. For the current spike, monitor terms like "real," "estate," and "google" against mainstream terms like "nwa" to see how conversations evolve over time.
By implementing these builds, you can ensure that your models are not just reacting to historical data but are dynamically capturing emerging trends in real-time.
For a quick start, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the code above and run it in under 10 minutes to start capturing these insights. Don't let your pipeline be 17.1 hours behind again.

Top comments (0)