Your pipeline missed a significant 24h momentum spike of +0.353, indicative of a rising sentiment around cultural themes. This anomaly is particularly striking when you consider that the leading language for sentiment was French, with a 28.9-hour lead time. The article cluster, titled "Chinese Culture Days brings music, dance and cultural exchange to Missouri Botan," highlights a vibrant cultural exchange happening right now. If your sentiment analysis model doesn’t account for multilingual origins or dominant entities, you could be lagging significantly behind in capturing emerging trends in cultural discourse.

French coverage led by 28.9 hours. Sv at T+28.9h. Confidence scores: French 0.85, English 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
The implications of this oversight are substantial. Your model missed this by 28.9 hours, which is a critical gap when it comes to reacting to real-time sentiment shifts. With the leading article in French and a strong cultural theme, you may end up missing out on insights that affect engagement strategies or content recommendations. This isn’t just a minor timing issue; it’s a structural gap that can lead to missed opportunities in sentiment-driven decision-making.
To catch up and leverage this momentum, we can use our API to filter by language and analyze the sentiment narratives. Here’s how to do that in Python:
import requests
*Left: Python GET /news_semantic call for 'culture'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/v1/topics"
params = {
"topic": "culture",
"lang": "fr"
}
response = requests.get(url, params=params)
data = response.json()
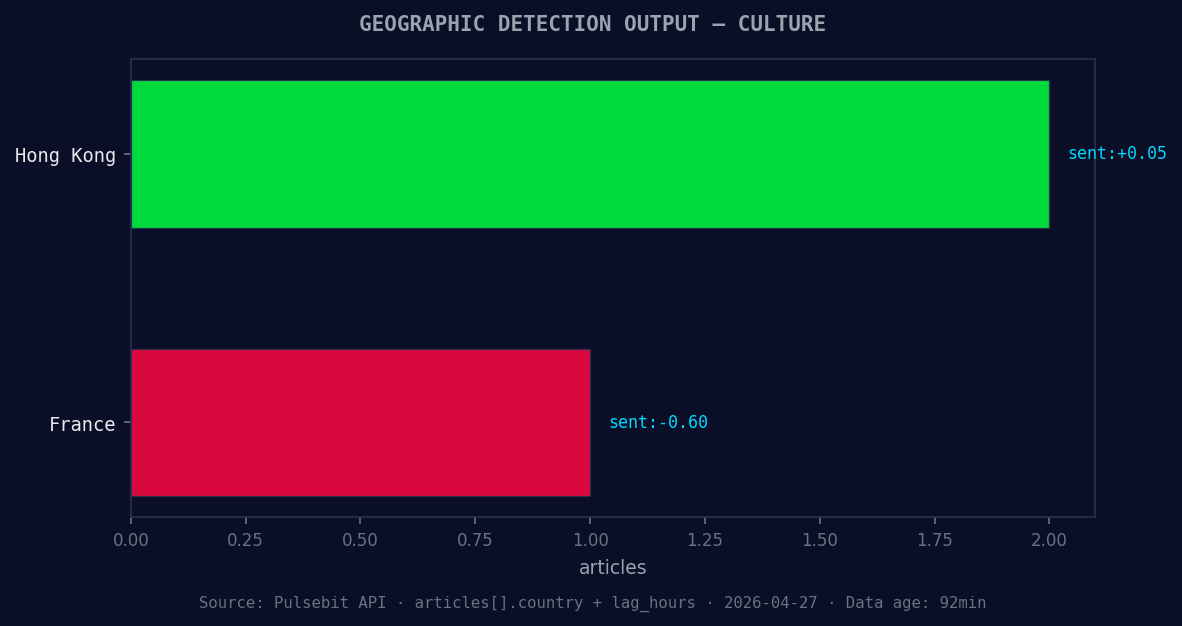
*Geographic detection output for culture. Hong Kong leads with 2 articles and sentiment +0.05. Source: Pulsebit /news_recent geographic fields.*
# Output the response for debugging
print(data)
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: culture, days, brings, music, dance."
sentiment_url = "https://api.pulsebit.com/v1/sentiment"
sentiment_response = requests.post(sentiment_url, json={"text": cluster_reason})
sentiment_data = sentiment_response.json()
# Output the sentiment analysis result
print(sentiment_data)
In this code, we first filter our query by the French language to hone in on culturally relevant topics. We then run the cluster reason string through our sentiment endpoint to analyze how the framing of this news is perceived. The resulting sentiment score from this analysis can offer deeper insights into public perception, allowing us to validate or adjust our understanding of the cultural themes emerging from the articles.
Here are three specific things to build with this sentiment spike pattern:
Cultural Sentiment Tracker: Create a dashboard that uses our geo filter to track sentiment over time for cultural topics in multiple languages. Set a threshold to alert you when momentum crosses +0.3, ensuring you’re always aware of emerging cultural narratives.
Meta-Sentiment Analyzer: Develop an endpoint that automatically runs cluster reasons through the sentiment analysis loop. This will help gauge the framing of narratives, especially when the score exceeds +0.4, indicating a strong sentiment that could impact audience engagement.
Thematic Engagement Plans: Use the forming themes—culture, google, cultural—to create targeted content recommendations. For example, if the momentum for "cultural" reaches above +0.2, trigger a campaign that highlights cultural events or articles, thus leveraging these insights for increased engagement.
If you want to get started integrating this functionality, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the above code and have it running in under 10 minutes, allowing you to catch up on cultural sentiment trends effectively. Let's not let another 28.9-hour gap slip by!

Top comments (0)