Your Pipeline Is 23.0h Behind: Catching Finance Sentiment Leads with Pulsebit
We recently stumbled upon a fascinating anomaly: a 24h momentum spike of +0.186, indicating a significant uptick in sentiment around finance. This spike was particularly pronounced in the Spanish press, which led with a story about the US 30-Year Yield hitting its highest level since 2007. The article, titled "US 30-Year Yield Hits Highest Since 2007 as Selloff Deepens," illustrates a clear sentiment shift that your current model might be missing.
The Problem
If your pipeline doesn’t account for multilingual origins or dominant entities, you could be lagging behind by a staggering 23.0 hours. In this case, the leading language was Spanish, and the dominant entity was the finance sector. Your model might be processing data in English and missing a significant narrative emerging in another language. This highlights a critical gap: if you're not capturing global sentiment in real-time, you're essentially blind to crucial market shifts.

Spanish coverage led by 23.0 hours. Tl at T+23.0h. Confidence scores: Spanish 0.85, English 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
To catch this spike before it becomes history, we can leverage our API effectively. Below is a Python snippet that filters by language and scores the meta-sentiment of the narrative framing itself.
import requests
*Left: Python GET /news_semantic call for 'finance'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
endpoint = "https://api.pulsebit.io/v1/articles"
params = {
"topic": "finance",
"lang": "sp",
"momentum": 0.186
}
response = requests.get(endpoint, params=params)
articles = response.json()
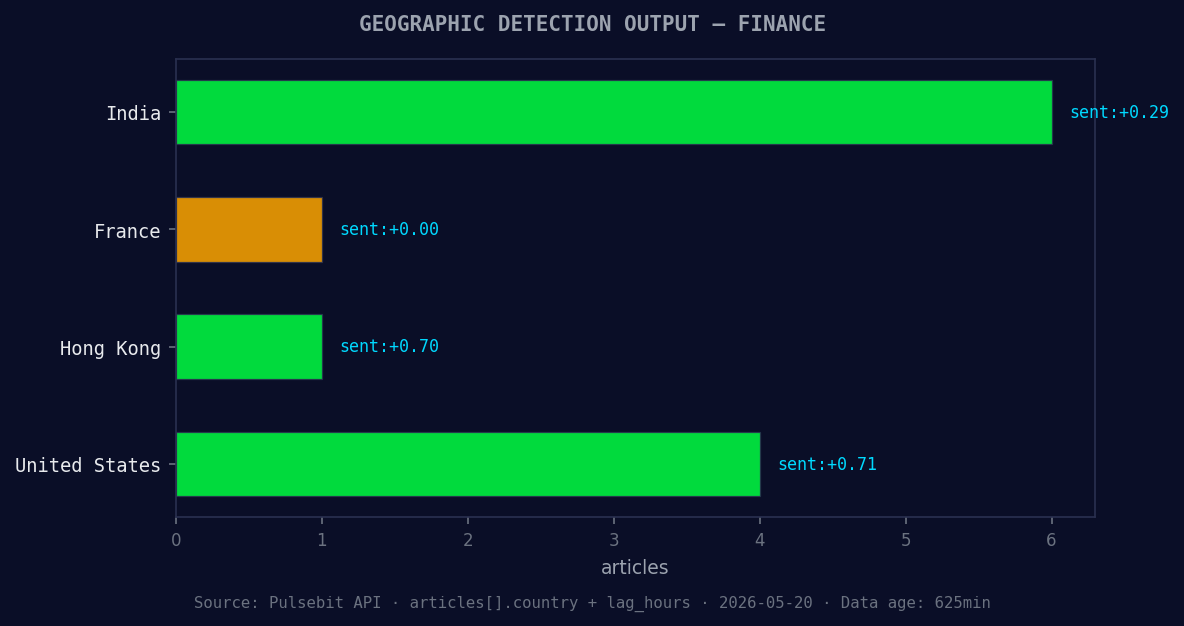
*Geographic detection output for finance. India leads with 6 articles and sentiment +0.29. Source: Pulsebit /news_recent geographic fields.*
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: 30-year, yield, hits, highest, since."
sentiment_endpoint = "https://api.pulsebit.io/v1/sentiment"
sentiment_response = requests.post(sentiment_endpoint, json={"text": cluster_reason})
sentiment_score = sentiment_response.json()
In this code, we're first querying the articles filtered for the finance topic in Spanish. Following that, we send the narrative framing back through our sentiment endpoint to capture the sentiment score.
Three Builds Tonight
Now, let’s talk about three specific builds that you can implement using this pattern.
Geo Filter on Leading Language: Create a real-time alert system that triggers when a momentum spike in finance is detected in a non-English language. Set the threshold at +0.186, focusing on the Spanish press for immediate insights.
Meta-Sentiment Loop: Develop a dashboard that visualizes the sentiment score of clustered themes in finance. Use the meta-sentiment API to regularly update the narrative framing, allowing you to assess how the sentiment evolves over time.
Forming Themes Analysis: Build an analysis tool that highlights forming themes from different sources like Google and Yahoo Finance. Monitor keywords like "30-year," "yield," and "hits" while comparing them against mainstream sentiment, giving you a broader view of emerging trends.
Get Started
You can dive into this right away at pulsebit.lojenterprise.com/docs. In under 10 minutes, you can copy, paste, and run this code to catch those hidden finance sentiment leads. Don’t let your pipeline fall behind!

Top comments (0)