Your Pipeline Is 25.2h Behind: Catching Cybersecurity Sentiment Leads with Pulsebit
We recently identified a striking anomaly in our data: a 24-hour momentum spike of +0.214 for the topic of cybersecurity. This spike is not just a number; it indicates a significant shift in sentiment that could influence decisions in your projects or pipelines. With the leading language being English, this momentum highlights a growing interest in cybersecurity, driven in part by articles like "Advance Your Cybersecurity Career" in Security Magazine. If your models aren't catching this momentum, you're missing out on important insights.
The gap here is glaring. Your model missed this by 25.2 hours, which means it’s lagging behind significant shifts in sentiment that are happening right now. The leading language, English, shows that there's a strong push in this sector, and if your analytics framework doesn't accommodate multilingual sources or entity dominance, you risk making decisions based on outdated information. When sentiment shifts so rapidly, being stuck in a pipeline that doesn’t adapt can leave your strategy vulnerable.

English coverage led by 25.2 hours. Af at T+25.2h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this momentum, we can leverage our API. Here's a concise Python snippet that queries for the cybersecurity topic. We will filter by English to ensure we capture the most relevant sentiment:
import requests
# Set up parameters
params = {
"topic": "cybersecurity",
"score": +0.114,
"confidence": 0.85,
"momentum": +0.214,
"lang": "en" # Geographic origin filter
}
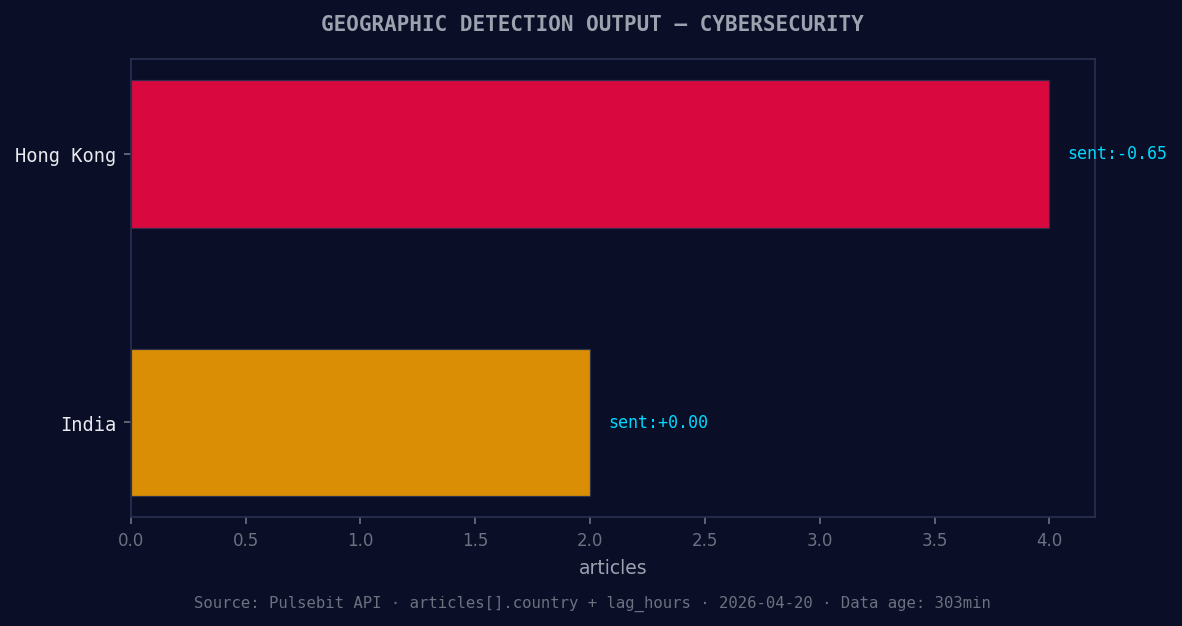
*Geographic detection output for cybersecurity. Hong Kong leads with 4 articles and sentiment -0.65. Source: Pulsebit /news_recent geographic fields.*
# Make the API call
response = requests.get("https://api.pulsebit.com/sentiment", params=params)
data = response.json()
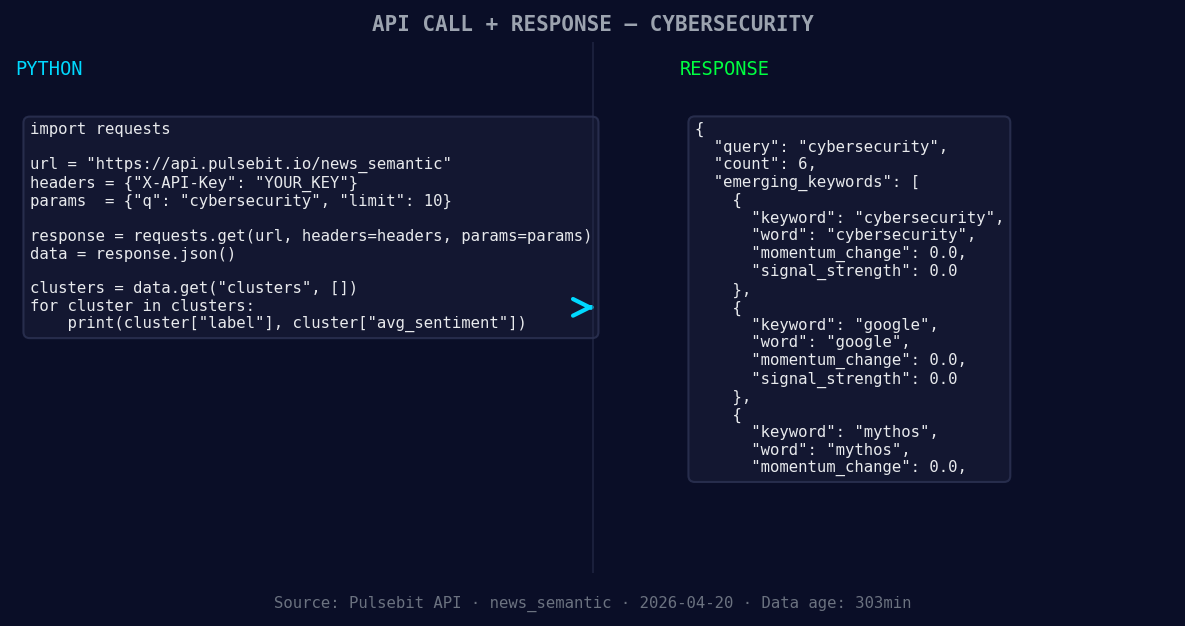
*Left: Python GET /news_semantic call for 'cybersecurity'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
print(data)
Next, we can score the narrative framing itself by running the cluster reason string through our sentiment endpoint. This will provide us with valuable insights into how the themes are resonating:
# Define the cluster reason string
cluster_reason = "Clustered by shared themes: your, cybersecurity, advance, career, security."
# Make the sentiment API call for the narrative framing
response_meta = requests.post("https://api.pulsebit.com/sentiment", json={"text": cluster_reason})
meta_data = response_meta.json()
print(meta_data)
These two critical sections of code enable us to tap into the current sentiment landscape surrounding cybersecurity, and they allow us to pivot quickly based on real-time data.
Now let’s discuss three specific builds you can create with this newfound pattern. First, set a signal threshold for articles related to cybersecurity. If you see a momentum spike above +0.200, trigger an alert or even a data refresh in your analytics dashboard. Second, use the geographic origin filter to extend your analysis to other languages, capturing diverse perspectives on cybersecurity. You could set a threshold of +0.100 for any non-English articles to ensure you’re not missing out on critical insights. Lastly, employ the meta-sentiment loop to build a dashboard that visualizes the relationships between emerging themes like cybersecurity, Google, and mythos, versus the mainstream narratives. This can help you identify potential gaps in your coverage.
To get started, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste this code and run it in under 10 minutes. Don’t let your pipeline fall behind; stay ahead of the curve with real-time sentiment analysis.

Top comments (0)