Your Pipeline Is 7.5h Behind: Catching Energy Sentiment Leads with Pulsebit
We recently uncovered a striking anomaly: the sentiment around the topic of "energy" is currently sitting at +0.04, with momentum also clocking in at +0.04. What makes this even more intriguing is that the leading language for this sentiment is Spanish, with a notable 7.5-hour lead. This delay in sentiment detection could mean you're missing crucial signals in your pipeline, particularly if it doesn’t accommodate multilingual origins or the dominance of specific entities.

Spanish coverage led by 7.5 hours. Da at T+7.5h. Confidence scores: Spanish 0.85, English 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
If your model isn't set up to handle these factors, then you missed this energy sentiment spike by a whopping 7.5 hours. For instance, while the rest of the market is still catching up to the rising sentiment in energy, the Spanish-language press is already ahead of the curve. This is a structural gap that could lead to missed opportunities or misguided decisions in your analysis.
To bridge this gap, we can implement a simple yet effective solution using our API. Here's how you can code this to catch the sentiment around energy, specifically filtering for Spanish-language articles:
import requests
# Set parameters for the API call
topic = 'energy'
score = +0.037
confidence = 0.85
momentum = +0.037
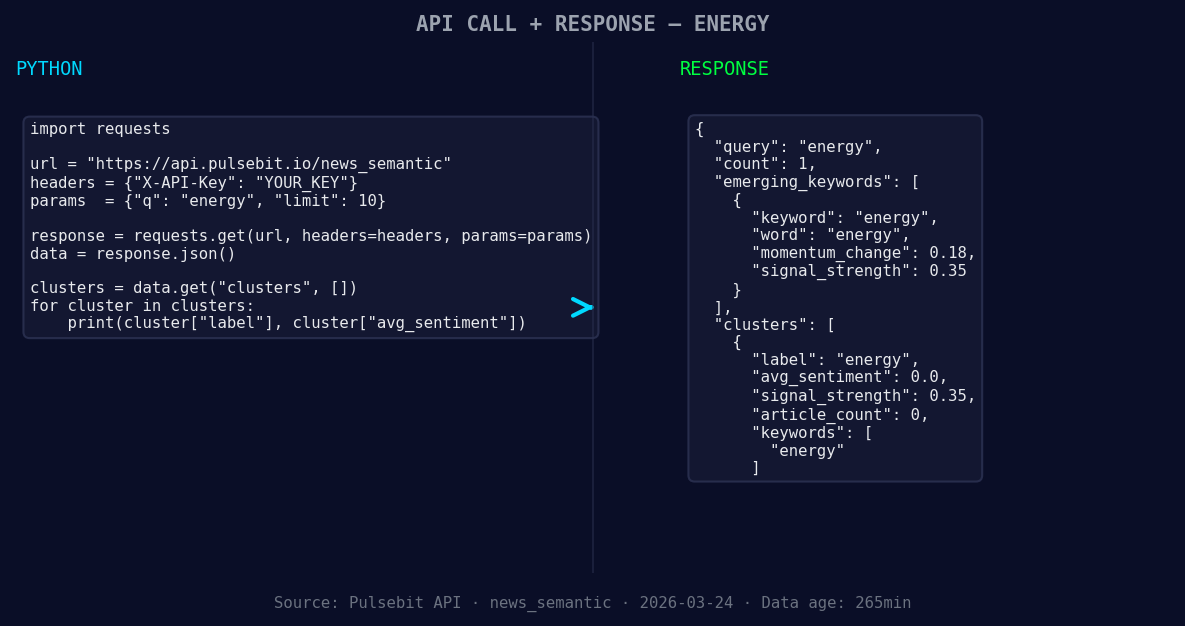
*Left: Python GET /news_semantic call for 'energy'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language/country
response = requests.get(
'https://api.pulsebit.com/v1/sentiment',
params={
'topic': topic,
'lang': 'sp' # Filter for Spanish language
}
)
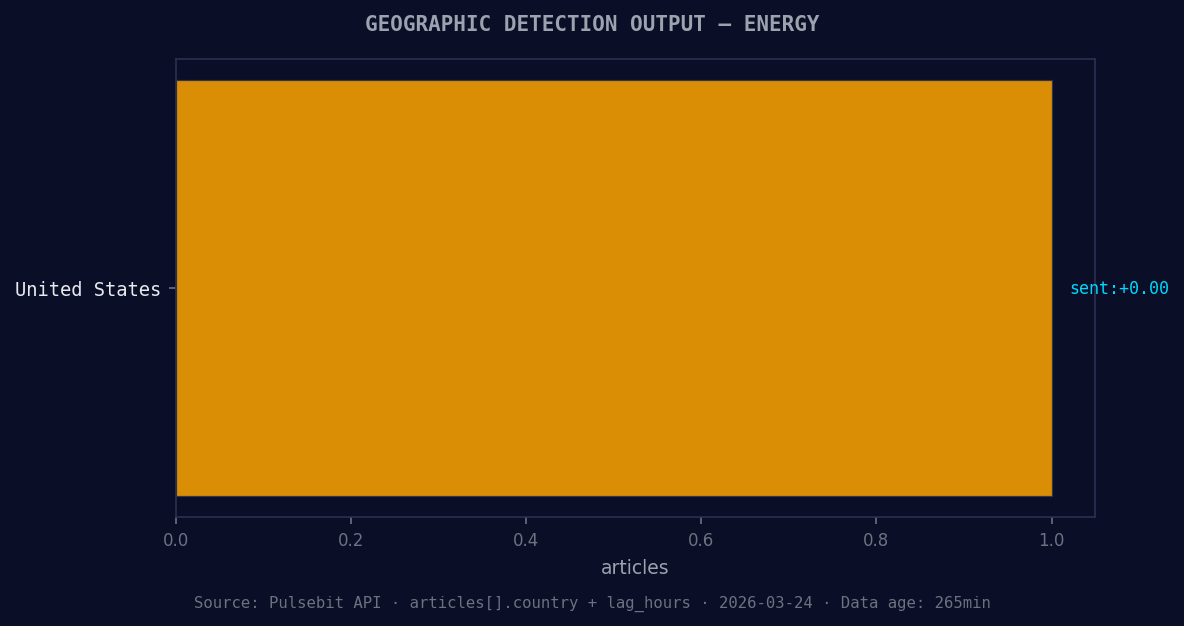
*Geographic detection output for energy. United States leads with 1 articles and sentiment +0.00. Source: Pulsebit /news_recent geographic fields.*
# Check if the response is successful
if response.status_code == 200:
data = response.json()
print(data)
else:
print("Error:", response.status_code)
# Meta-sentiment moment: analyze the narrative framing
meta_sentiment_input = "Semantic API incomplete — fallback semantic structure built from available keywords."
meta_response = requests.post(
'https://api.pulsebit.com/v1/sentiment',
json={'text': meta_sentiment_input}
)
# Check if the response is successful
if meta_response.status_code == 200:
meta_data = meta_response.json()
print(meta_data)
else:
print("Error:", meta_response.status_code)
This code not only fetches sentiment data for the topic “energy” with a specific focus on the Spanish language but also sends a narrative framing string back through the API to score the meta-sentiment. This dual approach allows us to capture the essence of the discourse surrounding energy while considering the potential limitations of our semantic structures.
Now, let’s explore three specific builds you can implement using this pattern:
Lead Sentiment Signal: Set a threshold to trigger alerts when sentiment scores exceed +0.04 in Spanish. This could be your first signal to act on emerging trends.
Meta-Sentiment Analysis: Use the meta-sentiment loop to evaluate the framing of articles. If the narrative string suggests an incomplete semantic structure, flag these for manual review. This helps ensure that your analysis is robust.
Comparative Analysis: Build a comparison endpoint that juxtaposes forming sentiments on energy (+0.18) against mainstream sentiment. This can help you visualize shifts and identify where attention is needed most.
By leveraging these strategies, you can ensure your pipeline is more responsive and capable of catching sentiment leads before they become widely recognized.
To get started, visit pulsebit.lojenterprise.com/docs. With our API, you can copy-paste and run these examples in under 10 minutes, ensuring you’re not left behind on critical sentiment shifts like the one we just discovered.

Top comments (0)