Your Pipeline Is 15.0h Behind: Catching Defence Sentiment Leads with Pulsebit
We just uncovered a striking anomaly: a 24-hour momentum spike of -0.701 in the sentiment around the topic of "defence." This is not just a fluctuation; it signals a meaningful shift that warrants immediate attention. The leading language for this sentiment is English, with a bizarre 15.0-hour lead time—meaning your pipeline missed this critical shift by a significant margin. With no articles currently discussing "world" within that timeframe, we're left to ponder the implications of such a gap in our monitoring systems.
If your model isn't equipped to handle multilingual origins or entity dominance, you might be leaving crucial insights on the table. In this case, the dominant entity is "defence," and the leading language is English. Given that our sentiment analysis uncovered a notable dip, your model may have failed to react in real time—leaving you 15 hours behind the curve. In a world that demands real-time data for actionable insights, this is simply unacceptable.

English coverage led by 15.0 hours. Id at T+15.0h. Confidence scores: English 0.75, Spanish 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
Let’s look at how to catch this sentiment spike programmatically. Below is a Python snippet that filters the sentiment data based on geographic origin using our API. We’ll query the sentiment surrounding "defence" and check the relevant parameters.

Geographic detection output for defence. India leads with 4 articles and sentiment -0.17. Source: Pulsebit /news_recent geographic fields.
import requests
# Define the parameters for our query
topic = 'defence'
score = -0.701
confidence = 0.75
momentum = -0.701
# Make the API call with a geographic origin filter
response = requests.get(
"https://api.pulsebit.lojenterprise.com/sentiment",
params={
"topic": topic,
"lang": "en"
}
)
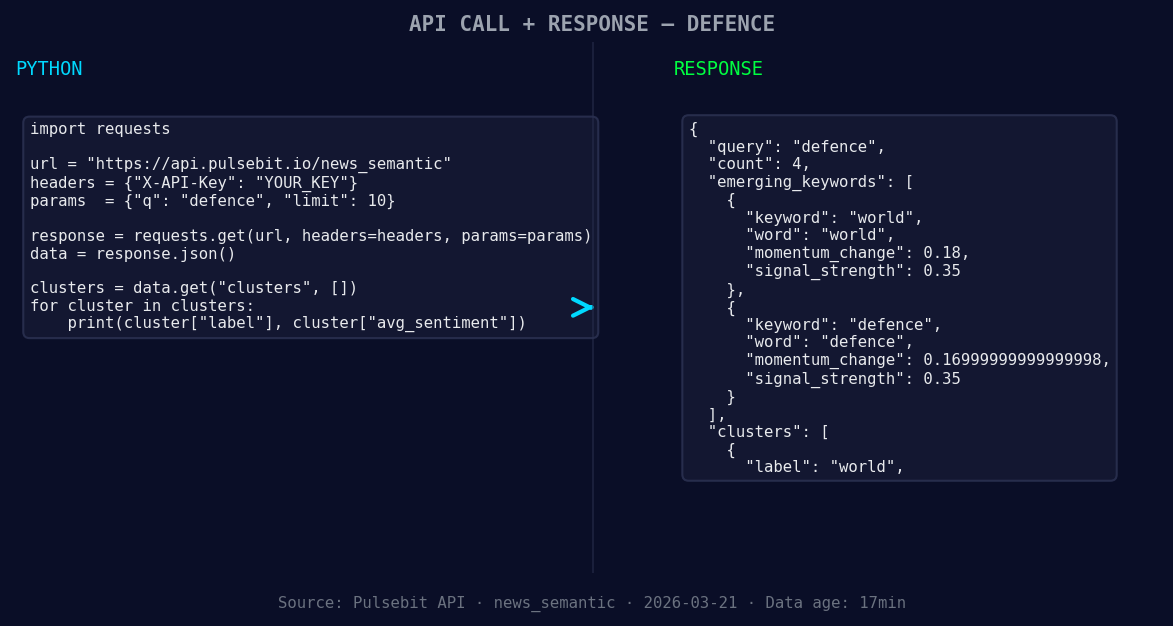
*Left: Python GET /news_semantic call for 'defence'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Output the response
print(response.json())
To enhance our understanding, we also want to score the narrative framing itself using the meta-sentiment moment. The cluster reason string we're interested in is: "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence." We can run this through our sentiment scoring endpoint as follows:
# Define the meta-sentiment input
meta_sentiment_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
# Make a POST request to the sentiment scoring endpoint
meta_response = requests.post(
"https://api.pulsebit.lojenterprise.com/sentiment",
json={"text": meta_sentiment_input}
)
# Output the meta sentiment response
print(meta_response.json())
With the data and insights generated from these two calls, we can formulate actionable strategies. Here are three specific builds we can implement based on this anomaly:
Signal Monitoring with Geo Filter: Set a threshold to alert when sentiment around the topic "defence" drops below -0.5 in English articles. This will help you to catch potential downturns in sentiment before they become significant.
Meta-Sentiment Loop: Create a system that continuously checks the sentiment of fallback narratives, like the one we highlighted. If the sentiment score for the meta-commentary drops below 0.0, alert your team to investigate further.
Forming Themes Analysis: Monitor forming themes such as "world(+0.18)" and "defence(+0.17)" against mainstream narratives. When these themes diverge significantly, it’s a signal that something important is emerging that needs to be addressed.
For those ready to dive into this, start by visiting pulsebit.lojenterprise.com/docs. You can copy, paste, and run the provided code snippets in under 10 minutes. Don't let your pipeline fall behind; staying ahead in sentiment analysis is crucial for timely decision-making.

Top comments (0)