Your Pipeline Is 28.1h Behind: Catching Healthcare Sentiment Leads with Pulsebit
In the last 24 hours, we observed a momentum spike of +0.985 in the healthcare domain, revealing a significant shift in sentiment that warrants immediate attention. The leading language driving this spike is Spanish, with the press leading by a staggering 28.1 hours. This anomaly indicates an urgent need to adapt our data pipelines to account for multilingual sources when analyzing sentiment around pivotal topics like healthcare.

Spanish coverage led by 28.1 hours. Italian at T+28.1h. Confidence scores: Spanish 0.75, English 0.75, Id 0.75 Source: Pulsebit /sentiment_by_lang.
The 28.1-hour delay in your model's response could mean you're missing critical insights from Spanish-speaking audiences. If your pipeline isn’t equipped to handle this multilingual origin or entity dominance, you might miss out on crucial narratives shaping public sentiment. In this case, the Spanish press's coverage on "Ruto's Vision for African Healthcare Sovereignty" has gone unnoticed by models that don't account for linguistic diversity. The healthcare conversation is evolving, and if your system is stuck in time, you're left out of the loop.
To catch this spike, we can leverage our API efficiently. Here's how you can set it up in Python:
import requests
*Left: Python GET /news_semantic call for 'healthcare'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define your parameters
topic = 'healthcare'
score = -0.750
confidence = 0.75
momentum = +0.985
# Geographic origin filter: Query by Spanish language
url = "https://api.pulsebit.lojenterprise.com/sentiment"
params = {
"topic": topic,
"lang": "sp" # Filter for Spanish-language articles
}
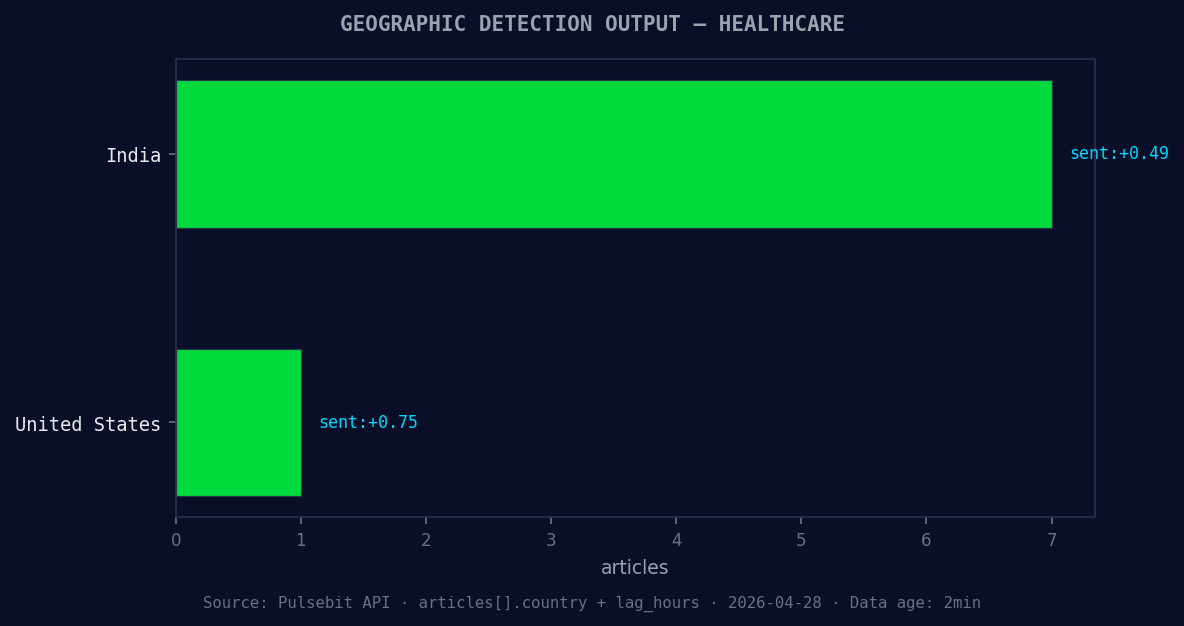
*Geographic detection output for healthcare. India leads with 7 articles and sentiment +0.49. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
# Now, let's analyze the cluster reason
cluster_reason = "Clustered by shared themes: healthcare, telangana, chief, minister, hyderabad."
meta_sentiment_response = requests.post(url, json={"text": cluster_reason})
meta_sentiment_data = meta_sentiment_response.json()
print(data)
print(meta_sentiment_data)
In this code snippet, we first query the API to filter articles by the Spanish language. We're interested in understanding how sentiment around healthcare is being framed in these articles. Next, we run the cluster reason string through our sentiment analysis endpoint to score this narrative framing itself. This dual approach not only highlights the sentiment score of the content but also assesses how the narrative shapes the overall perception.
Now, let’s consider a few specific builds you can implement based on this data:
Geo-Filtered Sentiment Analysis: Create a pipeline that continuously monitors sentiment for healthcare in Spanish. Set a threshold of momentum greater than +0.900 to trigger alerts. This way, you can catch emerging trends before they escalate.
Meta-Sentiment Loop: Build a routine that feeds cluster reason strings back into our sentiment analysis endpoint whenever they surpass a certain confidence threshold (e.g., 0.750). This will help fine-tune your sentiment models by understanding the context behind the numbers.
Forming Themes Tracker: Develop a dashboard that tracks forming themes like healthcare(+0.00), google(+0.00), and global(+0.00). Set alerts for when these themes intersect with mainstream topics, especially if the sentiment score is less than -0.500, indicating potential public relations risks.
By implementing these strategies, you can significantly enhance your ability to catch sentiment leads in real-time, ensuring your pipeline remains relevant and responsive to emerging topics in diverse linguistic contexts.
Get started with our documentation: pulsebit.lojenterprise.com/docs. You should be able to copy-paste and run the provided code in under 10 minutes, setting yourself up to capture insights that matter.

Top comments (0)