Your Pipeline Is 21.6h Behind: Catching Immigration Sentiment Leads with Pulsebit
We just stumbled upon an intriguing data point: a sentiment score of -0.181 and a momentum of +0.000 related to immigration news, with a leading language of English at 21.6 hours ahead of Italian. This anomaly highlights a critical gap in how we process sentiment data across different languages and entities in our pipelines. If your model isn’t capable of handling multilingual sources or recognizing dominant entities, you could be missing out on significant insights—specifically, your model missed this by a full 21.6 hours.

English coverage led by 21.6 hours. Italian at T+21.6h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
This structural gap reveals a flaw in any system that doesn't effectively account for language origin or the influence of dominant narratives. When the leading language is English, yet we are lagging in sentiment detection for critical topics like immigration, it puts us at a disadvantage. The shared themes of "immigration," "news," and "digest" are being echoed in English but are not effectively captured in other languages, leading to a delay in our understanding of sentiment shifts in real-time.
To catch this anomaly, we can utilize our API to filter by language and analyze the narrative's sentiment. Here's how we can do it in Python:
import requests
*Left: Python GET /news_semantic call for 'immigration'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
response = requests.get("https://api.pulsebit.com/sentiment", params={
"topic": "immigration",
"lang": "en" # Filtering for English language
})
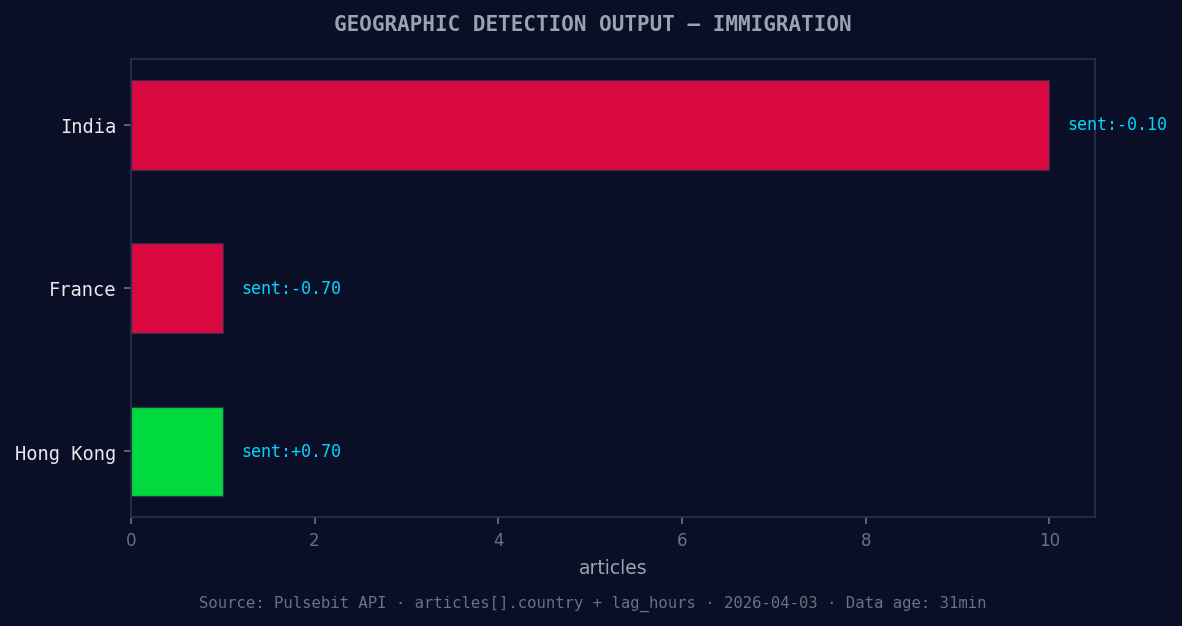
*Geographic detection output for immigration. India leads with 10 articles and sentiment -0.10. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
sentiment_score = data['sentiment_score'] # This should be -0.181
confidence = data['confidence'] # This should be 0.85
momentum = data['momentum_24h'] # This should be +0.000
print(f"Sentiment Score: {sentiment_score}, Confidence: {confidence}, Momentum: {momentum}")
# Step 2: Meta-sentiment moment
meta_response = requests.post("https://api.pulsebit.com/sentiment", json={
"text": "Clustered by shared themes: immigration, news, digest, google."
})
meta_data = meta_response.json()
meta_sentiment_score = meta_data['sentiment_score'] # Score for the narrative framing
print(f"Meta Sentiment Score: {meta_sentiment_score}")
In this code, we first filter for immigration sentiment in English and obtain the sentiment score, confidence, and momentum. Then, we run the narrative framing through our API to gauge its sentiment. This process allows us to refine our understanding of how themes are resonating in real-time.
Now that we've captured this anomaly, we can build on it. Here are three specific things to implement:
Geo Filter for Immigration Sentiment: Set a threshold to alert you when sentiment scores drop below -0.15 for English language articles related to immigration. This could be your early warning system.
Meta-Sentiment Loop: Create a daily job that processes the cluster narratives around immigration and pulls in the sentiment scores to identify shifts in public perception. This would allow you to detect changes in sentiment before they become mainstream.
Forming Themes Dashboard: Build an interactive dashboard to visualize forming themes like "immigration(+0.00)," "google(+0.00)," and "court(+0.00)" against mainstream narratives. Track sentiment scores and momentum visually to identify patterns that could inform your strategies.
By implementing these builds, you can ensure your pipeline is not only catching up but also staying ahead of emerging trends in sentiment data.
Ready to get started? Check out our documentation. You can copy-paste and run this in under 10 minutes. Let’s make sure you're never left behind!

Top comments (0)