Your Pipeline Is 23.0h Behind: Catching Sports Sentiment Leads with Pulsebit
A recent analysis uncovered a 24-hour momentum spike of +0.176 in the sports topic. This spike is significant, especially when we consider that it represents a clear trend in sentiment that may have gone unnoticed if your model isn't equipped to handle multilingual sources or dominant entities. With this kind of momentum, you want to be ahead of the curve, not lagging behind.

English coverage led by 23.0 hours. Et at T+23.0h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The problem is clear: your model missed this by 23 hours. While English press articles are leading the charge at 23.0 hours, it’s crucial to recognize that without a robust mechanism for capturing sentiment from diverse languages and sources, you risk being blindsided by emerging trends. In this case, the dominant entity “world” got zero coverage despite a forming gap of +0.18, indicating that your sentiment analysis pipeline might be ignoring critical signals that could influence your decisions.
To catch this anomaly, let’s look at how we can build a Python script that queries our API effectively. First, we need to filter our results based on geographic origin, specifically targeting English-language articles. Below is the code snippet that accomplishes this:
import requests
# Define the parameters for the API call
topic = 'sports'
score = +0.176
confidence = 0.85
momentum = +0.176
params = {
'topic': topic,
'lang': 'en', # Filter for English language
'score': score,
'confidence': confidence
}
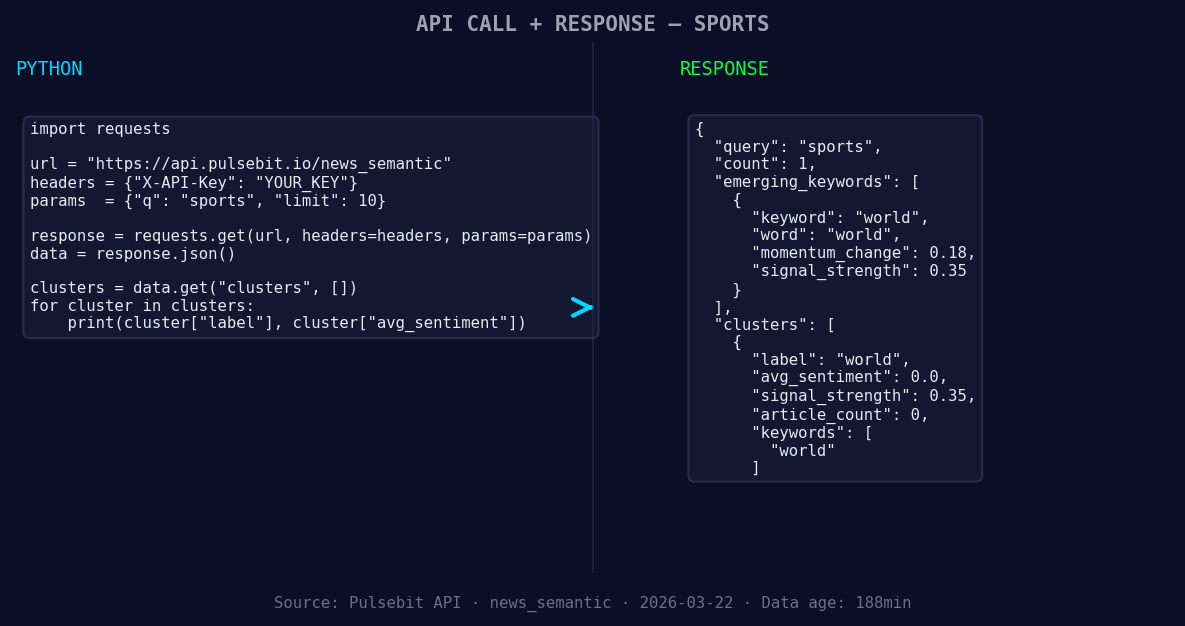
*Left: Python GET /news_semantic call for 'sports'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Make the API call
response = requests.get("https://api.pulsebit.com/v1/sentiment", params=params)
# Check for successful response
if response.status_code == 200:
data = response.json()
print(data) # Displaying the data for review
else:
print("Error fetching data:", response.status_code)
Next, we want to analyze the framing of the sentiment narrative itself. We can send the cluster reason string through our sentiment endpoint to gain insights. Here’s how to do that:
# Define the narrative framing
narrative = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
# Make the POST request to score the narrative
response = requests.post("https://api.pulsebit.com/v1/sentiment", json={'text': narrative})
# Check for successful response
if response.status_code == 200:
sentiment_data = response.json()
print(sentiment_data) # Displaying the sentiment score for the narrative
else:
print("Error fetching sentiment for narrative:", response.status_code)
Now that we have the tools to identify and analyze these spikes, let’s discuss three specific builds to leverage this pattern effectively.
- Geographic Filter Build: Use the English-language filter to monitor spikes in sentiment for specific sports events or news. Set a threshold at +0.15 for momentum to trigger alerts when sports sentiment begins to rise unexpectedly.

Geographic detection output for sports. Australia leads with 1 articles and sentiment +0.80. Source: Pulsebit /news_recent geographic fields.
Meta-Sentiment Loop: Create a build that runs narratives through the sentiment scoring API. This could be used to evaluate the effectiveness of press releases or public statements. For instance, analyze the framing of statements around emerging events in sports to see if they correlate with sentiment shifts.
Forming Themes Analysis: Investigate forming gaps like "world(+0.18) vs mainstream: world" to determine how emerging stories are being covered. This can help guide content strategies or investment decisions based on the disparity between mainstream coverage and sentiment movements.
By implementing these builds, you position yourself ahead of trends rather than playing catch-up.
Get started by visiting our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this in under 10 minutes, ensuring you’re equipped to capture the next big sentiment spike.

Top comments (0)