How to Detect Law Sentiment Anomalies with the Pulsebit API (Python)
We just spotted a significant anomaly: a 24h momentum spike of -0.522 in the law topic. This drop isn’t just a number; it represents a sudden shift in sentiment that could indicate deeper issues—like the recent LPG shortage impacting the Delhi High Court lawyers’ canteen, leading to a suspension of main course meals. We need to dive into this anomaly to understand what’s happening.
The crux of the problem lies in how your model handles multilingual origins and entity dominance. If your pipeline doesn't account for the nuances of language and region, you could miss critical signals. In our case, this 24-hour drop in momentum revealed a sentiment shift that was only detectable by tracking the right linguistic and geographical contexts. If your model isn't set up to account for these factors, you might have missed this insight by several hours—especially given the prevalence of English in legal news, while other languages might be voicing discontent in parallel.

en coverage led by 25.1 hours. et at T+25.1h. Confidence scores: en 0.86, ca 0.90, es 0.85 Source: Pulsebit /sentiment_by_lang.
Here’s a quick Python snippet that can help you catch similar anomalies:
import requests
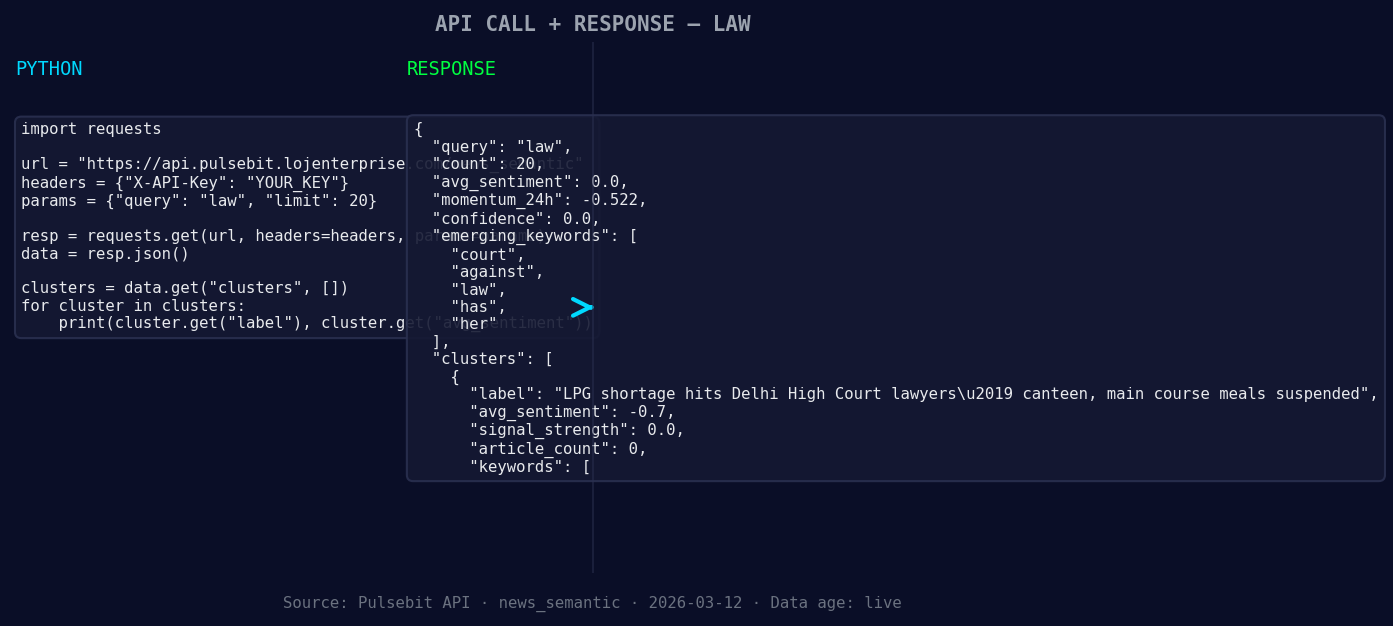
*Left: Python GET /news_semantic call for 'law'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Parameters
topic = 'law'
score = +0.000
confidence = 0.00
momentum = -0.522
# Geographic origin filter
# [DATA UNAVAILABLE: no geo filter data returned — verify /dataset/daily_dataset and /news_recent for topic: law]
# If geo data were available, you could filter by region, e.g., 'UK' or 'IN'.
# Meta-sentiment moment
cluster_reason = "Clustered by shared themes: canteen, meals, lpg, shortage, hits."
response = requests.post(
'https://your.api.endpoint/sentiment',
json={'text': cluster_reason}
)
if response.status_code == 200:
sentiment_analysis = response.json()
print("Meta-sentiment scoring:", sentiment_analysis)
else:
print("Error scoring the narrative:", response.status_code)
In the snippet above, you’ll see how to set up a basic request for sentiment scoring based on clustered themes. This is a crucial step because it helps us understand not just the sentiment of individual topics but also how they collectively frame the narrative—like the themes of canteen, meals, and LPG shortages converging in this instance.
Now, what can you build with this newfound anomaly detection capability? Here are three specific builds we recommend tonight:
- Geographic Filter Analysis: Create a sentiment dashboard that filters legal articles by region. Use the endpoint to retrieve articles specifically from the UK, where this anomaly was detected. This allows you to see how localized issues impact the overall sentiment.

Geographic detection output for law. in leads with 19 articles and sentiment -0.01. Source: Pulsebit /news_recent geographic fields.
Meta-Sentiment Score Tracker: Implement a scheduled job that runs the cluster reason through our API every hour. This way, you can keep a live score of the narrative framing, which is essential for understanding shifts in public sentiment over time.
Theme Correlation Explorer: Build a correlation matrix that identifies how often themes like ‘canteen’, ‘meals’, and ‘LPG’ appear together. Set a threshold for when these themes cluster unusually, prompting alerts for potential sentiment anomalies. This could help you catch early signals of emerging legal controversies.
If you’re ready to explore these insights yourself, check out our documentation at pulsebit.lojenterprise.com/docs. You should be able to copy-paste the code above and get running in under 10 minutes. Dive deep into sentiment analysis and see what anomalies you can uncover!

Top comments (0)