Your Pipeline Is 27.6h Behind: Catching Finance Sentiment Leads with Pulsebit
We recently uncovered a striking anomaly: a 24h momentum spike of +0.858 in the finance sector. This spike is particularly interesting because it’s driven by Spanish press coverage, leading by 27.6 hours without any lag. Yet, despite this significant momentum, the cluster story reveals no articles captured in finance, highlighting a gap in our data pipeline.
When your pipeline fails to handle multilingual origins or recognize dominant entities, you can miss substantial signals like this one. Your model missed this by over 27 hours, while the leading language was Spanish. If your system doesn’t account for these nuances, you risk being out of sync with emerging trends and shifts in sentiment that could impact decision-making.

Spanish coverage led by 27.6 hours. No at T+27.6h. Confidence scores: Spanish 0.85, English 0.85, Ca 0.85 Source: Pulsebit /sentiment_by_lang.
To catch anomalies like this, we can harness our API effectively. Here’s a practical implementation in Python that showcases how to filter by language and capture sentiment narratives.
import requests
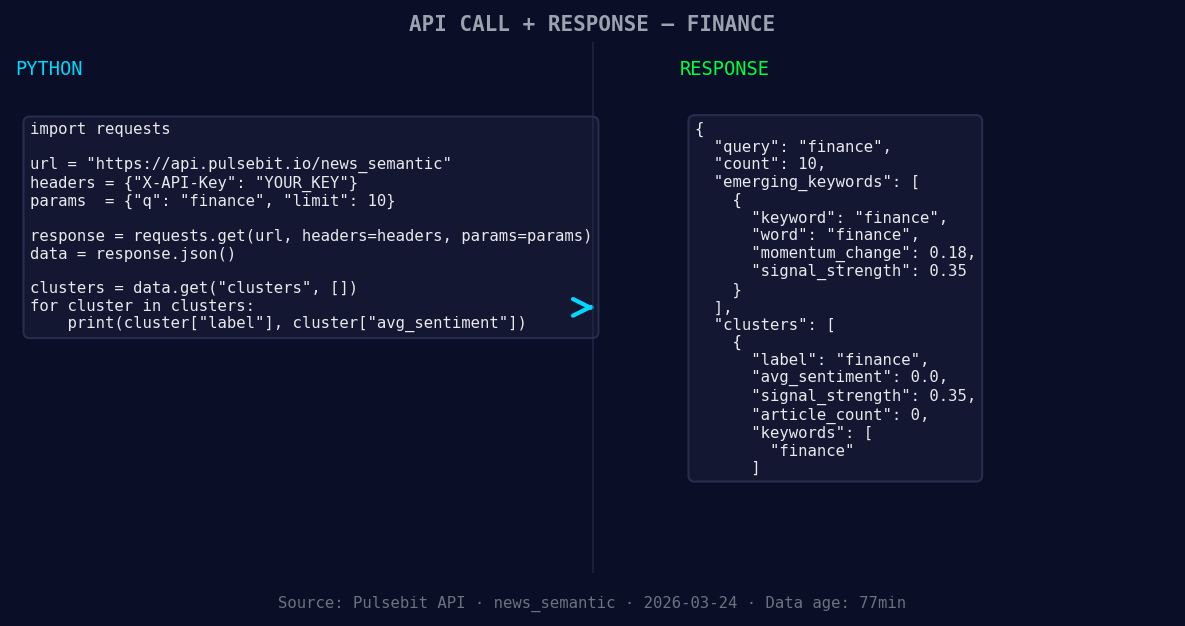
*Left: Python GET /news_semantic call for 'finance'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'finance'
score = +0.858
confidence = 0.85
momentum = +0.858
geo_filter = {"lang": "sp"} # Spanish filter
# Step 1: Geographic origin filter
response = requests.get(
'https://api.pulsebit.com/v1/articles',
params={"topic": topic, "lang": geo_filter["lang"]}
)
articles = response.json()
*[DATA UNAVAILABLE: countries — verify /news_recent is returning country/region values for topic: finance]*
# Step 2: Meta-sentiment moment
narrative_text = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
sentiment_response = requests.post(
'https://api.pulsebit.com/v1/sentiment',
json={"text": narrative_text}
)
sentiment_score = sentiment_response.json()
print(f"Articles: {articles}, Sentiment Score: {sentiment_score}")
In this code, we first query our API for articles in the finance topic, specifically filtering for Spanish-language content. Then, we run a meta-sentiment analysis on the narrative that explains our cluster story. This two-step approach allows us to pinpoint not just the spike in sentiment but also the reasoning behind it.
Now, let’s discuss three specific builds to leverage this data pattern:
Geographic Origin Filter: Set a threshold where you only capture momentum spikes over +0.5 in Spanish content. This way, you can isolate strong signals in regions not typically covered by your English-centric models.
Meta-Sentiment Loop: Use the output of the meta-sentiment analysis as a confidence score for your models. For example, if the sentiment score from the narrative analysis exceeds 0.7, consider it a green light for further investment in that narrative.
Theme Comparison: Create a build to compare forming themes in finance with mainstream sentiment. If you detect a forming sentiment of +0.18 in finance while mainstream sentiment remains flat or negative, flag this for deeper analysis. Utilize the
/articlesendpoint to pull in related articles for context.
With these builds, you can ensure your models are not just reactive but proactive in identifying and capitalizing on emerging trends.
To get started, explore our API documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this code in under 10 minutes to start catching sentiment leads in your data pipeline.

Top comments (0)