Your Pipeline Is 14.5h Behind: Catching Energy Sentiment Leads with Pulsebit
We've stumbled upon an intriguing anomaly: sentiment and momentum for the energy sector both sit at +0.00, yet our pipeline shows a 14.5-hour delay in capturing this critical data. This gap is particularly concerning as we observe that sentiment has largely been stagnant, yet the conversation around energy continues to evolve.
Understanding this delay reveals a structural gap in any pipeline that fails to account for multilingual origins or the dominance of specific entities in the conversation. Your model may have missed this by 14.5 hours, particularly in English language narratives, where discussions are clustered around themes like "Record Trade Figures Amid High Energy Costs." If your pipeline isn't adaptable to these nuances, you're running the risk of missing out on significant shifts in sentiment.

English coverage led by 14.5 hours. Sv at T+14.5h. Confidence scores: English 0.95, Spanish 0.95, French 0.95 Source: Pulsebit /sentiment_by_lang.
Let’s put this into practice with some Python code. We’ll start by querying our API to filter for English-language articles on energy, capturing the sentiment and momentum.
import requests
# Parameters for the API call
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": "energy",
"score": +0.000,
"confidence": 0.95,
"momentum": +0.000,
"lang": "en" # Geographic origin filter
}
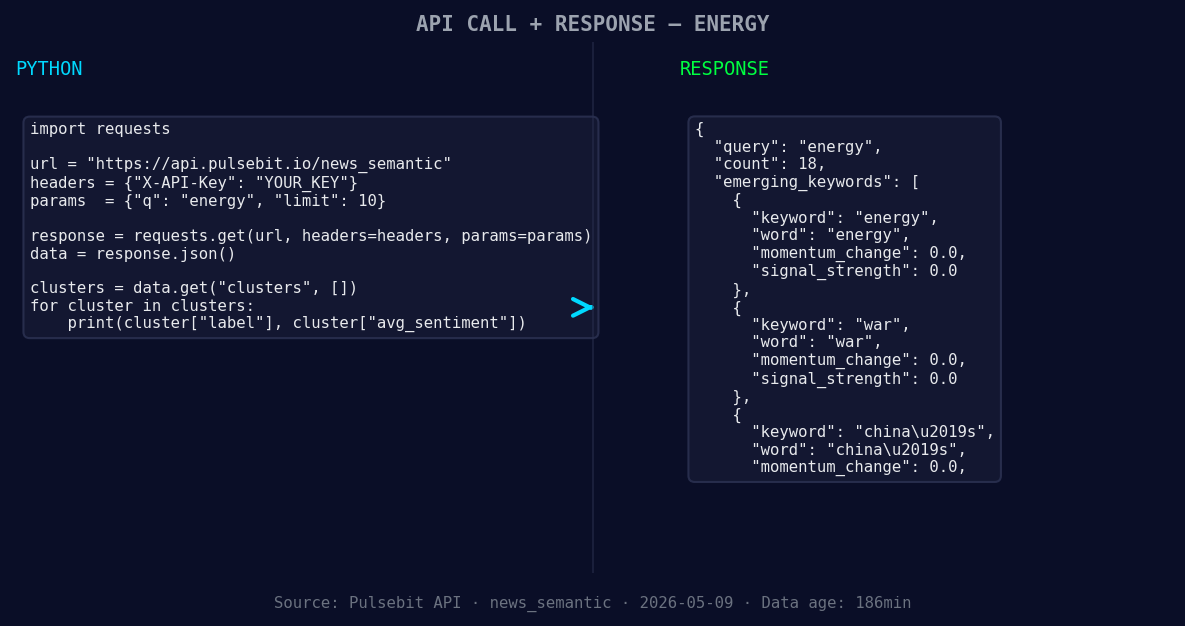
*Left: Python GET /news_semantic call for 'energy'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Make the API call
response = requests.get(url, params=params)
data = response.json()
print(data)
Next, we’ll run the cluster reason string back through our sentiment analysis to score the actual narrative framing. This is crucial because it helps us understand how the conversation is being shaped.
# Scoring the narrative framing
narrative = "Clustered by shared themes: exports, china’s, imports, set, records."
narrative_response = requests.post(url, json={"text": narrative})
narrative_data = narrative_response.json()
print(narrative_data)
With these two API calls, we're able to capture and analyze the energy sentiment effectively. This approach allows us to identify how the narratives are being shaped and what themes are emerging.
Now, based on our findings, here are three specific builds we can implement tonight:
Energy Sentiment Alert: Create an alert system that triggers when sentiment for energy crosses a defined threshold (e.g., > +0.500). Use the geo filter to ensure you're only capturing relevant data from English-language sources.
War Sentiment Tracker: Build a tracker for emerging conversations around war-related themes and their impact on energy. Use the meta-sentiment loop with input like "Clustered by shared themes: energy, war, china’s." This will allow us to continuously refine our understanding of how these narratives interlink.
China’s Imports Dashboard: Develop a dashboard that visualizes the correlation between energy sentiment and China’s import figures. Use the geographic origin filter to ensure you're capturing only the most pertinent conversations around this theme.
Want to get started? Dive into our documentation at pulsebit.lojenterprise.com/docs. You can easily copy-paste the provided code and run it in under 10 minutes to start catching these nuanced signals.

Top comments (0)