Your 24-hour momentum spike of +0.904 in education sentiment is not just a number; it represents a seismic shift in discussion around the topic. This spike suggests an urgent wave of interest that is being largely overlooked, particularly in the context of artificial intelligence, which has just emerged as a forming theme with a +0.18 score. This anomaly indicates that while mainstream discussions have stalled, there's a growing momentum that we need to tap into.
However, if your pipeline isn't handling multilingual origins or entity dominance effectively, you might have missed this momentum by a staggering 27.2 hours. This oversight is particularly concerning given that the leading language in this spike is English, which means your model is lagging behind in capturing critical insights. The lack of articles discussing artificial intelligence is a glaring signal that your system may not be equipped to recognize shifting narratives, ultimately leaving you out of the loop when it comes to emerging trends.

English coverage led by 27.2 hours. Et at T+27.2h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this spike in momentum, we can leverage our API efficiently. Below is a Python snippet that captures the essence of this opportunity:
import requests
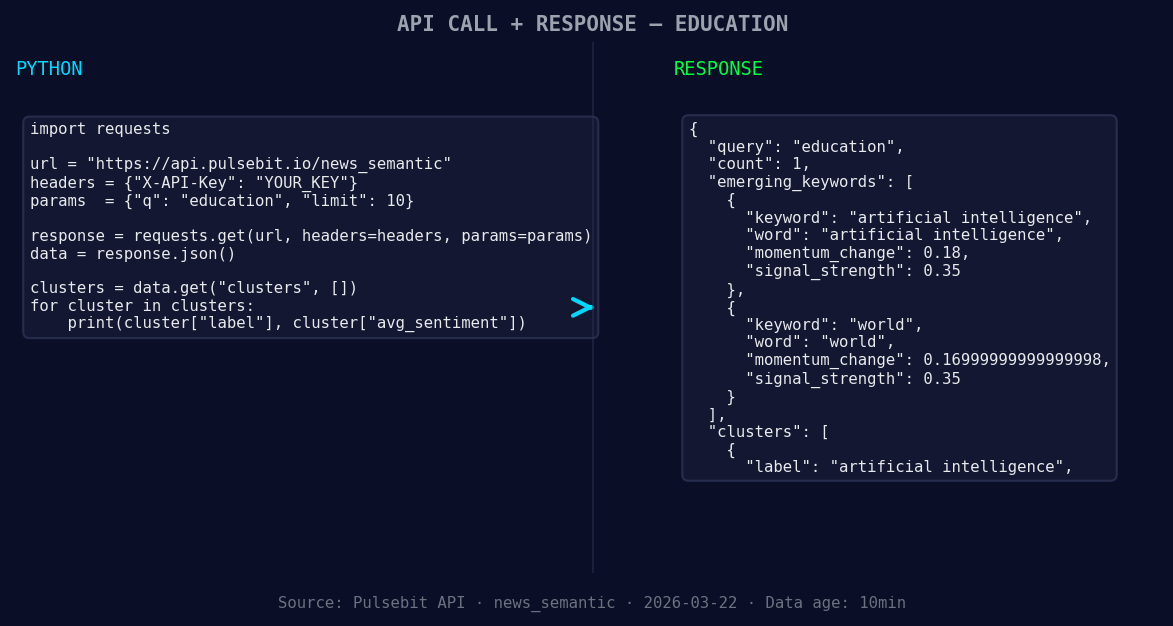
*Left: Python GET /news_semantic call for 'education'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'education'
score = +0.904
confidence = 0.85
momentum = +0.904
language = 'en'
# Geographic origin filter
response_geo = requests.get(
'https://api.pulsebit.com/v1/sentiment',
params={'topic': topic, 'lang': language}
)
# Print the response from the geographic filter
print(response_geo.json())
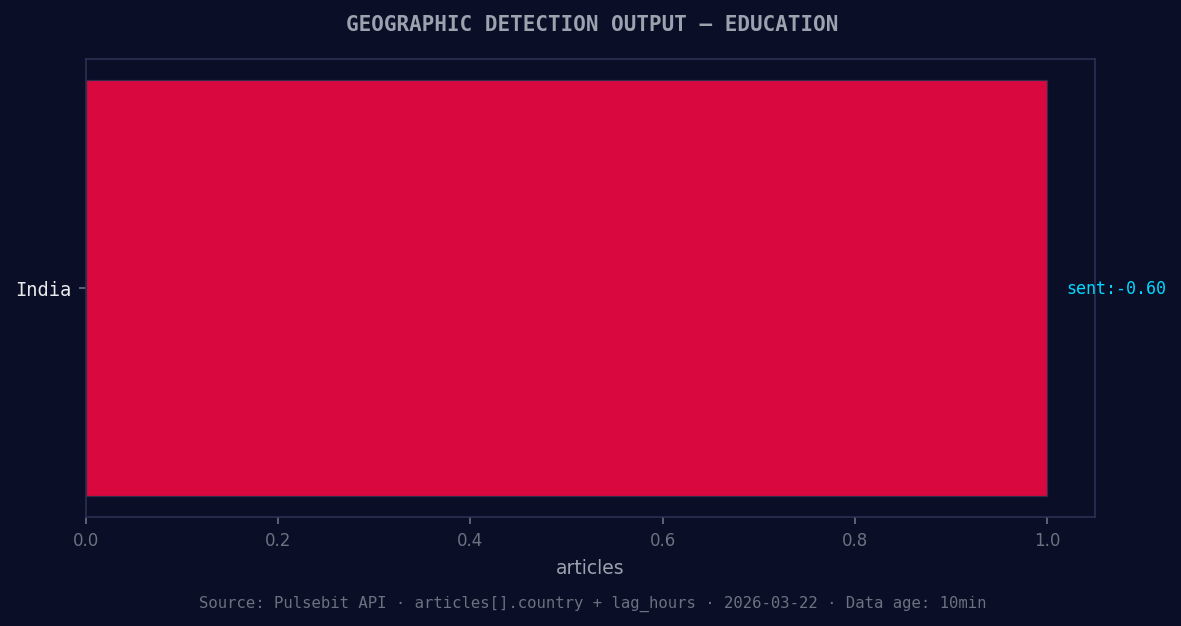
*Geographic detection output for education. India leads with 1 articles and sentiment -0.60. Source: Pulsebit /news_recent geographic fields.*
# Meta-sentiment moment
meta_sentiment_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
response_meta_sentiment = requests.post(
'https://api.pulsebit.com/v1/sentiment',
json={'text': meta_sentiment_input}
)
# Print the meta sentiment analysis result
print(response_meta_sentiment.json())
In this code, we first filter the sentiment data for the topic of education in English. This geographic origin filter ensures that we capture the relevant narratives without being skewed by other languages. Then, we pass a string that summarizes the reasoning for our semantic gap back through the sentiment scoring API. By doing this, we can assess the narrative framing itself, which allows us to understand not just the spike but why it matters.
Now, let's discuss three specific builds you can implement tonight to capitalize on this opportunity:
Spike Catcher: Create a signal that triggers alerts when the momentum score exceeds a threshold of +0.8. This will help you catch emerging narratives early. Implement this by referencing the educational sentiment data in your pipeline.
Geo-Driven Insights: Use the geographic origin filter to analyze sentiment trends in specific regions. For instance, if you notice a rise in sentiment for artificial intelligence in English from the UK, you can tailor your content or marketing strategies accordingly.
Narrative Feedback Loop: Implement a feedback mechanism where you regularly check the meta-sentiment scores for keywords related to your primary topics. For example, every time "world" or "artificial intelligence" trends, run it through the cluster reasoning API to understand the framing and adjust your content strategy accordingly.
To get started, head over to pulsebit.lojenterprise.com/docs. You can copy-paste the code snippets and run them in under 10 minutes to start catching these insightful trends. The key is to stay ahead of the curve and not let critical data slip through the cracks.

Top comments (0)