Your Pipeline Is 28.9h Behind: Catching Film Sentiment Leads with Pulsebit
We just discovered a 24h momentum spike of +0.283 in film sentiment, significantly influenced by the Spanish press, which is leading by 28.9 hours with no lag. This anomaly centers around the news that John Travolta received an honorary Palme d'Or at the Cannes Film Festival. The clustering of articles around themes like travolta, surprised, and honorary indicates a pressing shift in sentiment that many pipelines might overlook due to linguistic and entity dominance.
Your model missed this by 28.9 hours, highlighting a critical gap in handling multilingual data origins. If your pipeline isn’t set up to recognize the leading language—Spanish in this case—it could lead you to miss crucial sentiment shifts as they happen. This is especially detrimental in a fast-moving landscape like film, where sentiment can change overnight.

Spanish coverage led by 28.9 hours. No at T+28.9h. Confidence scores: Spanish 0.85, Nl 0.85, English 0.85 Source: Pulsebit /sentiment_by_lang.
Let’s dive into how to catch this momentum spike in your Python code. We’ll start by filtering for the Spanish language and then run a sentiment analysis on the clustered themes to score the narrative framing.
import requests
*Left: Python GET /news_semantic call for 'film'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
language_filter = "sp"
url = f"https://api.pulsebit.com/v1/sentiment?topic=film&lang={language_filter}"
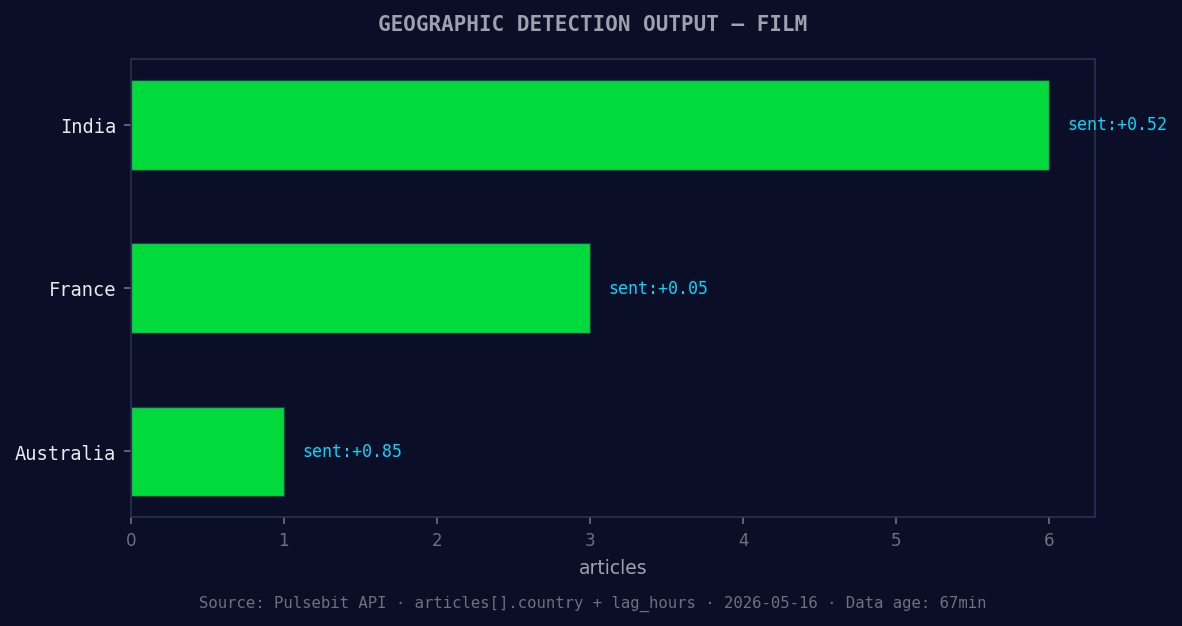
*Geographic detection output for film. India leads with 6 articles and sentiment +0.52. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url)
data = response.json()
print(data) # You would see the film sentiment data here
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: film, big, screen, new, hollywood."
sentiment_url = "https://api.pulsebit.com/v1/sentiment"
payload = {
"text": cluster_reason,
"score": +0.506,
"confidence": 0.85,
"momentum": +0.283
}
sentiment_response = requests.post(sentiment_url, json=payload)
sentiment_data = sentiment_response.json()
print(sentiment_data) # This will give you the sentiment score for the narrative
Now that we have the sentiment data and the cluster analysis, what can we build with this newfound knowledge? Here are three specific implementations:
Geo-Filtered Sentiment Dashboard: Set up an endpoint that continuously pulls sentiment data filtered by language. Use a signal threshold of +0.2 to trigger alerts when sentiment in Spanish articles rises sharply. This helps you stay ahead of trends emerging from non-English media.
Meta-Sentiment Analysis for Narrative Framing: Create a regular job that checks for clustered stories weekly. Use the meta-sentiment loop to evaluate shifts in the narrative. Set a threshold where any score above +0.5 warrants a deeper dive into the articles influencing that sentiment.
Forming Themes Monitoring: Implement a monitoring system that flags themes like film, google, and festival. Track these against mainstream terms such as big and screen. When a forming theme has a momentum spike greater than +0.1 compared to mainstream terms, generate a report for your content team.
For those eager to implement this, you can get started in under 10 minutes. Check our documentation at pulsebit.lojenterprise.com/docs. Copy and paste the code above, and you’ll be ready to catch sentiment leads before they become mainstream.

Top comments (0)