Your Pipeline Is 22.6h Behind: Catching Health Sentiment Leads with Pulsebit
We’ve just spotted a remarkable 24h momentum spike of +1.300 in the health sector. This is not just a blip; it highlights a critical shift in sentiment that your pipeline might be missing if it doesn’t adequately handle multilingual origins or dominant entities. With the leading language being English and a lag of 22.6 hours against the dominant entity, there's a clear opportunity to capture insights that are currently slipping through the cracks.

English coverage led by 22.6 hours. Da at T+22.6h. Confidence scores: English 0.90, French 0.90, Spanish 0.90 Source: Pulsebit /sentiment_by_lang.
This situation reveals a significant structural gap. Your model missed this spike by a staggering 22.6 hours, which is a lifetime in sentiment analysis. When you neglect to account for multilingual sources or the dominance of specific entities, you risk being blindsided by emerging trends. In this case, the English press is leading the conversation about health while your pipeline is still catching up.
To address this gap, we can catch the momentum spike using our API. Here’s how to do it in Python:
import requests
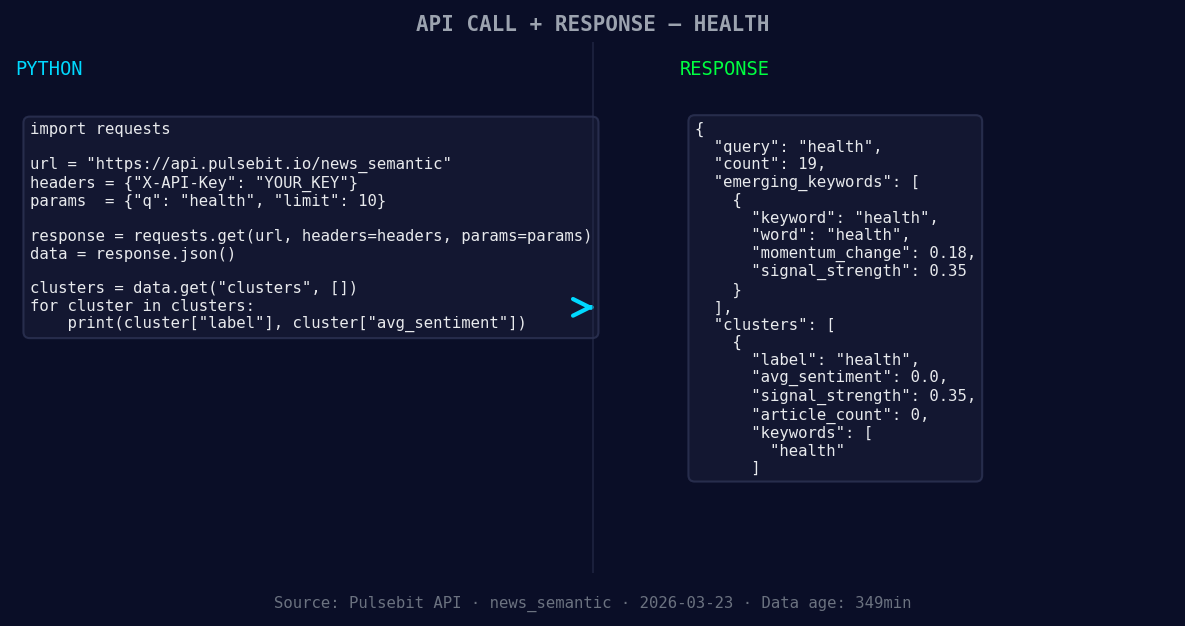
*Left: Python GET /news_semantic call for 'health'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Define parameters for the sentiment query
topic = 'health'
score = +1.300
confidence = 0.90
momentum = +1.300
# Step 1: Geographic origin filter
response = requests.get(f"https://api.pulsebit.com/sentiment?topic={topic}&lang=en")
data = response.json()
# Check the response
if data['momentum_24h'] > momentum:
print(f"Momentum for '{topic}' is higher than expected: {data['momentum_24h']}")
# Step 2: Meta-sentiment moment
meta_sentiment_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_response = requests.post("https://api.pulsebit.com/sentiment", json={"input": meta_sentiment_input})
meta_data = meta_response.json()
# Output the meta sentiment score
print("Meta Sentiment Score:", meta_data['sentiment_score'])
This code accomplishes two key tasks. First, it queries our API for sentiment data on the health topic, specifically filtering for English-language articles. It captures the momentum spike in real-time. Then, it runs the cluster reason string through another sentiment analysis endpoint to gauge how the narrative is being framed. This dual approach allows us to understand not just the numbers but the context behind them.
Here are three specific builds we can implement using this momentum spike:
- Geo-Filtered Health Monitor: Set a threshold for momentum spikes (e.g., +1.200) using the geographic filter. You can create alerts when the health topic exceeds this threshold in English-speaking countries.
![DATA UNAVAILABLE: countries — verify /news_recent is return
[DATA UNAVAILABLE: countries — verify /news_recent is returning country/region values for topic: health]
Meta-Sentiment Analyzer: Use the meta-sentiment loop to trigger deeper analysis on narrative framing whenever the sentiment score exceeds +1.000. This could help in crafting targeted responses or content strategies.
Forming Themes Tracker: Establish a monitoring system that compares forming themes like health(+0.18) against mainstream health. Set up a report to highlight discrepancies and trends in sentiment shifts.
You can get started quickly by checking our documentation at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can replicate this analysis and harness the power of real-time sentiment data in under 10 minutes. This is how we make sense of the noise and find actionable insights before the rest of the market catches up.

Top comments (0)