Your Pipeline Is 21.7h Behind: Catching Sports Sentiment Leads with Pulsebit
We recently uncovered a striking anomaly in our sentiment data: a sentiment score of +0.199 with a momentum of +0.000, pointing to a notable uptick in sports-related discussions. This finding reveals that while sentiment is rising, the momentum hasn't shifted, suggesting an opportunity that many pipelines might overlook. With a leading language sentiment peak at 21.7 hours, we have a chance to capitalize on discussions surrounding sports, betting, and finances.
The structural gap this exposes is profound. If your pipeline isn't designed to handle multilingual origins or entity dominance, you could be missing out on critical insights. Your model missed this by 21.7 hours, leaving you behind in understanding how sports and financial narratives intertwine, particularly in English-speaking regions. The dominant entity here is "sports," and without addressing this gap, you risk unearthing vital sentiment shifts far too late.

English coverage led by 21.7 hours. Nl at T+21.7h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly, we can leverage our API effectively. Here's how we do it in Python:
import requests
*Left: Python GET /news_semantic call for 'sports'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.lojenterprise.com/sentiment"
params = {
"topic": "sports",
"score": 0.199,
"confidence": 0.85,
"momentum": 0.000,
"lang": "en" # Filter for English
}
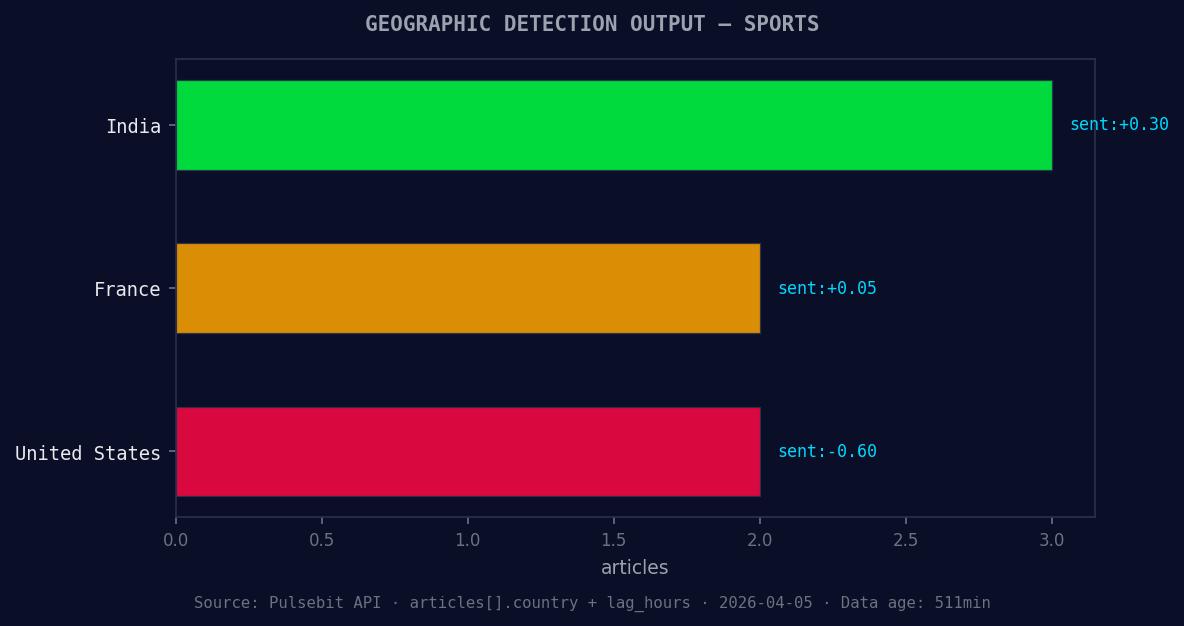
*Geographic detection output for sports. India leads with 3 articles and sentiment +0.30. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
sports_sentiment_data = response.json()
print(sports_sentiment_data)
Next, we need to analyze the meta-sentiment of our cluster reason. This step is essential for understanding the narrative framing itself. We’ll run the following input through our API to score the cluster:
# Step 2: Meta-sentiment moment
meta_sentiment_url = "https://api.pulsebit.lojenterprise.com/sentiment"
meta_input = {
"text": "Clustered by shared themes: waltair, division, sports, mela, gets."
}
meta_response = requests.post(meta_sentiment_url, json=meta_input)
meta_sentiment_data = meta_response.json()
print(meta_sentiment_data)
With this data in hand, we can build three specific signals tonight that will enhance our understanding of the sentiment landscape:
Geo-Filtered Sports Sentiment: Set a threshold for sentiment scores above +0.15 to identify rising discussions in sports across English-speaking regions. Use the geo filter to ensure you’re capturing relevant data from these areas.
Meta-Sentiment Analysis on Forming Themes: Run a loop on the themes forming around "sports," "google," and "college." Set a score threshold of +0.10 to identify budding narratives that could become significant.
Comparative Analysis on Mainstream Narratives: Compare the emerging sentiment on sports with mainstream topics like "waltair" and "division." Use a signal strength greater than 0.25 to highlight shifts in sentiment that indicate potential market movements.
By focusing on these specific signals, you’ll be better equipped to navigate the evolving landscape of sports sentiment and its financial implications.
If you're ready to dive in, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this in under 10 minutes. Let's keep our pipelines sharp and our insights timely!

Top comments (0)