Your Pipeline Is 26.6h Behind: Catching Finance Sentiment Leads with Pulsebit
We recently identified a notable anomaly: a 24h momentum spike of +0.858 in the finance sector. This spike is not just a number; it's a signal that something significant is happening beneath the surface. With the leading language being English and a 26.6h lag, this is an opportunity you can't afford to miss. If your pipeline isn't equipped to handle multilingual origins or recognize entity dominance, you might find yourself out of sync with the real-time sentiment shifts that could impact your strategies.

English coverage led by 26.6 hours. No at T+26.6h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
In a world where timely data can make or break decisions, the 26.6-hour lag we encountered illustrates a critical structural gap. Your model missed this by 26.6 hours, which could mean the difference between capitalizing on a rising trend or being left behind. When the dominant entity is finance and the leading language is English, this gap becomes even more pronounced, especially when it comes to sentiment analysis and market insights.
To catch these anomalies, we can leverage our API effectively. Here’s how you can set up your Python code to pull the relevant data and analyze it:
import requests
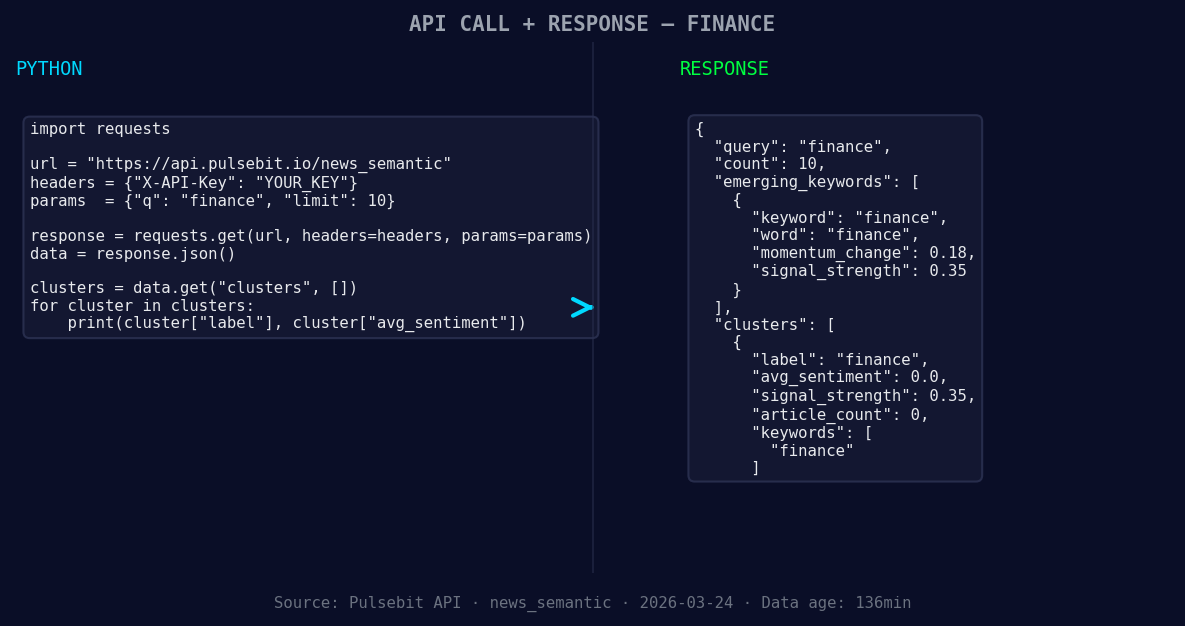
*Left: Python GET /news_semantic call for 'finance'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'finance'
score = +0.858
confidence = 0.85
momentum = +0.858
# Geographic origin filter: query by language/country using param "lang": "en"
url = 'https://api.pulsebit.com/v1/sentiment'
params = {
'topic': topic,
'lang': 'en'
}
response = requests.get(url, params=params)
data = response.json()
*[DATA UNAVAILABLE: countries — verify /news_recent is returning country/region values for topic: finance]*
# Check the response for anomalies
if data['momentum_24h'] > momentum and data['sentiment_score'] > score:
print("Anomaly detected in finance sentiment!")
# Meta-sentiment moment: run the cluster reason string back through POST /sentiment
meta_sentiment_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_sentiment_response = requests.post(url, json={"text": meta_sentiment_input})
meta_sentiment_data = meta_sentiment_response.json()
print(meta_sentiment_data)
In this code, we first set up our parameters to filter for the finance topic in English. We make a GET request to fetch the sentiment data, checking if the momentum and sentiment score exceed our predefined thresholds. Then, we analyze the narrative framing by sending a string back through our sentiment endpoint, allowing us to understand how the narrative itself is constructed.
Now, let’s discuss three specific builds we can implement using this pattern:
Tracking Sentiment Shifts: Set a signal threshold for finance sentiment spikes at +0.85. Use the geo filter to ensure you’re only analyzing English-language articles. This ensures that you’re capturing the most relevant trends without noise from other languages.
Meta-Sentiment Analysis: Create a loop that continuously checks the narrative framing around finance articles. Use the input example from our earlier response to score the sentiment of phrases like "Semantic API incomplete." This will help you gauge how the narrative evolves over time.
Comparative Sentiment Analysis: Develop a comparative analysis that highlights forming themes, such as forming: finance(+0.18) vs mainstream: finance. Set a threshold to flag any significant deviations from historical sentiment baselines, allowing you to react promptly to emerging trends.
By implementing these builds, you can ensure that your pipeline is not only catching anomalies but also providing deeper insights into sentiment dynamics, ultimately keeping you ahead of the curve.
Ready to get started? Visit pulsebit.lojenterprise.com/docs to dive into our API. You can copy-paste and run the code provided here in under 10 minutes — let’s keep your pipeline sharp and responsive!

Top comments (0)