Your Pipeline Is 26.2h Behind: Catching Stock Market Sentiment Leads with Pulsebit
We recently stumbled upon a fascinating anomaly: a 24h momentum spike of +0.933 related to the stock market. This spike was tied to two articles discussing the rising sentiment on the Dow, S&P 500, and Nasdaq due to hopeful news around an Iran deal. As we explored further, we realized that this was a clear signal of shifting market sentiment that any developer should be able to leverage effectively.
However, there’s a catch. If your pipeline doesn't accommodate for multilingual origins or the dominance of certain entities, you might have missed this critical update by a staggering 26.2 hours. In this case, the leading language was English, and the dominant entity was centered around the stock market with a notable lack of other languages in the mix. Missing this can result in delayed insights that could significantly impact your decision-making processes.

English coverage led by 26.2 hours. Id at T+26.2h. Confidence scores: English 0.90, French 0.90, Spanish 0.90 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly automatically, we can utilize our API. Here’s a straightforward implementation in Python to pull relevant sentiment data from our dataset:
import requests
*Left: Python GET /news_semantic call for 'stock market'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'stock market'
score = +0.632
confidence = 0.90
momentum = +0.933
# Geographic origin filter: Query by language
url = f"https://api.pulsebit.com/v1/sentiment?topic={topic}&lang=en"
response = requests.get(url)
data = response.json()
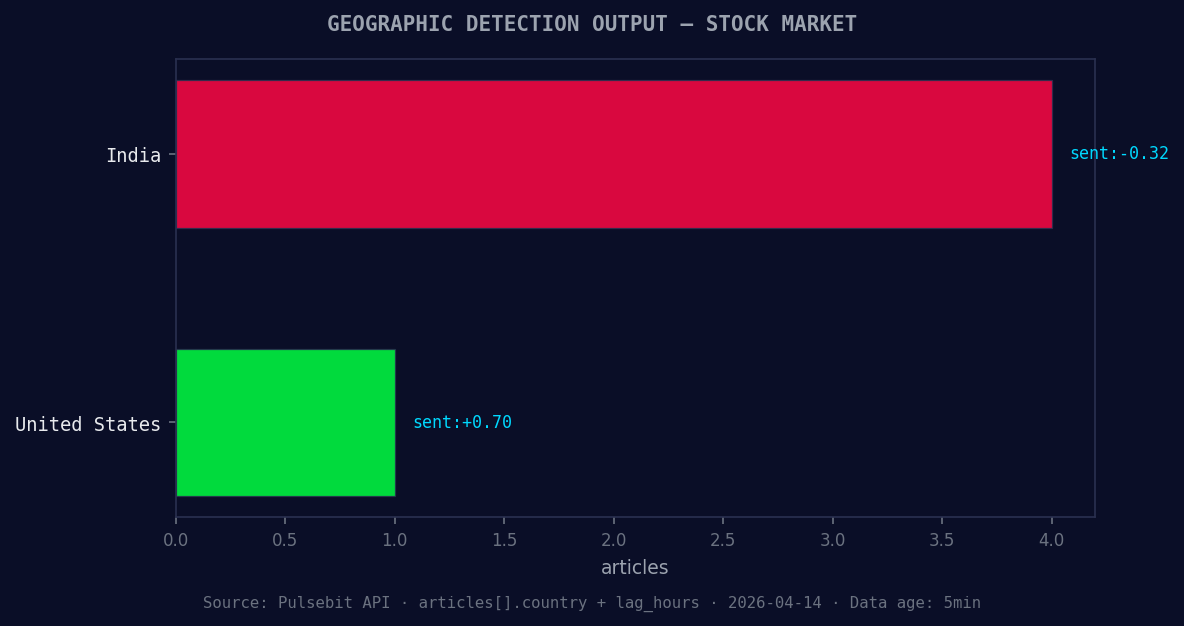
*Geographic detection output for stock market. India leads with 4 articles and sentiment -0.32. Source: Pulsebit /news_recent geographic fields.*
# Output relevant data
print(data)
# Meta-sentiment moment: Score the narrative framing
cluster_reason = "Clustered by shared themes: market, today:, 500, rises, back."
meta_sentiment_url = "https://api.pulsebit.com/v1/sentiment"
meta_response = requests.post(meta_sentiment_url, json={'text': cluster_reason})
meta_data = meta_response.json()
# Output meta sentiment data
print(meta_data)
This code does two essential things: first, it filters sentiment data by English language, ensuring you’re only processing the most relevant articles. Second, it runs the cluster reason string back through our sentiment analysis endpoint, giving you insights on how the narrative is framing itself. This dual approach not only captures the momentum spike but also provides context that enhances your understanding of the underlying sentiment.
Now that we've set up the groundwork, here are three specific builds we can implement with this pattern:
Threshold Alerting: Set a signal threshold for sentiment scores above +0.700 for the stock market. This could trigger alerts for any sudden changes in sentiment, allowing you to react rapidly to shifts in narrative.
Geo-Filtered Dashboard: Build a real-time dashboard that pulls in sentiment data specifically from English-language articles using the geo filter. This dashboard should visualize sentiment trends over time, allowing you to spot spikes like the recent +0.933 momentum easily.
Meta-Sentiment Analyzer: Create an endpoint that regularly scores the narrative framing of clustered articles. Use the meta-sentiment loop to categorize headlines around forming themes like “stock”, “market”, and “rises.” This will help you track how certain stories are being framed and perceived in the media.
By implementing these builds, you can take advantage of the latest sentiment data, ensuring you’re always in the loop. If you want to explore further, check out our documentation at pulsebit.lojenterprise.com/docs. You should be able to copy-paste and run these snippets in under 10 minutes, getting you up and running with the insights you need.

Top comments (0)