Your Pipeline Is 21.4h Behind: Catching Education Sentiment Leads with Pulsebit
We came across an intriguing anomaly: a 24h momentum spike of -0.391 in the education sector. This spike indicates a significant shift in sentiment, and it raises questions about how well your sentiment analysis pipeline is keeping up with real-time trends. If you're not accounting for multilingual origins or dominant entities, you could be missing out on critical insights—like this one—by as much as 21.4 hours. The leading language for this spike is English, which means we’re falling behind on a pertinent topic that deserves immediate attention.

English coverage led by 21.4 hours. Af at T+21.4h. Confidence scores: English 0.85, Ca 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
When your model doesn't handle multilingual origins or entity dominance effectively, it opens up a structural gap that can severely impact your insights. Imagine your pipeline lagging behind by 21.4 hours on a critical sentiment shift in education. If your system is only processing mainstream narratives, you might miss the nuanced discussions that emerge from specialized publications. This can lead to poor decision-making based on outdated or incomplete data.
Let’s get into the code that can help us catch these insights. We want to filter our queries to capture the latest sentiment in English and then run a meta-sentiment analysis on our clustered findings.
Here’s how to do it:
import requests
*Left: Python GET /news_semantic call for 'education'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": "education",
"lang": "en",
"score": -0.600,
"confidence": 0.85,
"momentum": -0.391
}
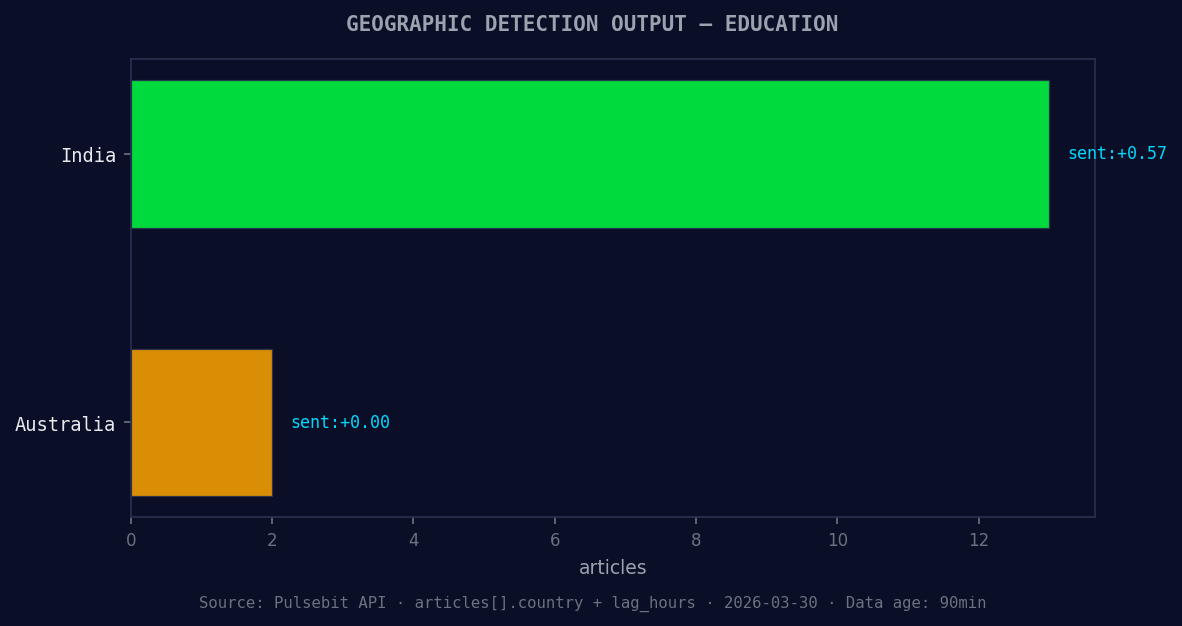
*Geographic detection output for education. India leads with 13 articles and sentiment +0.57. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
# Step 2: Meta-sentiment moment
meta_sentiment_input = "Clustered by shared themes: major, study, finds, special, education."
meta_response = requests.post(url, json={"text": meta_sentiment_input})
meta_data = meta_response.json()
print(data)
print(meta_data)
In this code, we first filter the sentiment analysis for the topic of education in English, using specific parameters that reflect the anomaly we identified. The second part runs a meta-sentiment analysis on the clustered reasons, allowing us to score the narrative framing itself. This two-step approach ensures that we’re not just catching the sentiment but also understanding the underlying themes that are driving it.
Now, let's explore three specific builds you could implement using this pattern:
Geo-targeted Alerts: Set up an alert system that triggers when sentiment drops below a threshold, say -0.5, specifically for educational topics in English. Use the geographic origin filter to ensure you're capturing localized sentiment shifts.
Meta-Sentiment Tracking: Create a dashboard that continually scores meta-sentiment narratives for clustered themes. By running these through our API, you can visualize how narratives evolve over time, providing context to the raw sentiment scores.
Content Creation Signals: Develop a content strategy that focuses on emerging themes like "education" and "awards" which are currently forming. Set a signal that tracks when the sentiment for these themes crosses a certain threshold, prompting content creation to capture the narrative while it's hot.
You can get started on this journey by visiting pulsebit.lojenterprise.com/docs. We believe you can copy-paste and run this in under 10 minutes, enabling you to enhance your sentiment analysis pipeline right away.

Top comments (0)