Your Pipeline Is 25.5h Behind: Catching Finance Sentiment Leads with Pulsebit
We just uncovered a significant anomaly: a 24h momentum spike of +0.847 in finance-related sentiment. This spike, driven primarily by two articles discussing a "Talent Search in Japanese Finance Sector," indicates a noteworthy shift in sentiment that you definitely don’t want to miss. The leading language is English, and it’s interesting to note that this sentiment surge is emerging just 0.0 hours behind the actual event.
The Problem
If your pipeline isn’t equipped to handle multilingual origins or dominant entities, you might be missing critical insights like this one by 25.5 hours. This disconnect can lead to a significant lag in your response to emerging trends. Here, the English press led the charge, and if your model isn't capable of capturing this, you risk operating on outdated information. Imagine missing a key shift in sentiment that could inform your trading or investment strategies; that's what you face when you're 25.5 hours behind the curve.

English coverage led by 25.5 hours. Af at T+25.5h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
To catch this momentum spike effectively, we can write a Python script that queries our API for the necessary data. Here’s how we can do it:
import requests
# Parameters for the API call
topic = 'finance'
lang = 'en'
score = -0.047
confidence = 0.85
momentum = +0.847
*Left: Python GET /news_semantic call for 'finance'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter
response = requests.get(f'https://api.pulsebit.com/articles?topic={topic}&lang={lang}')
articles = response.json()
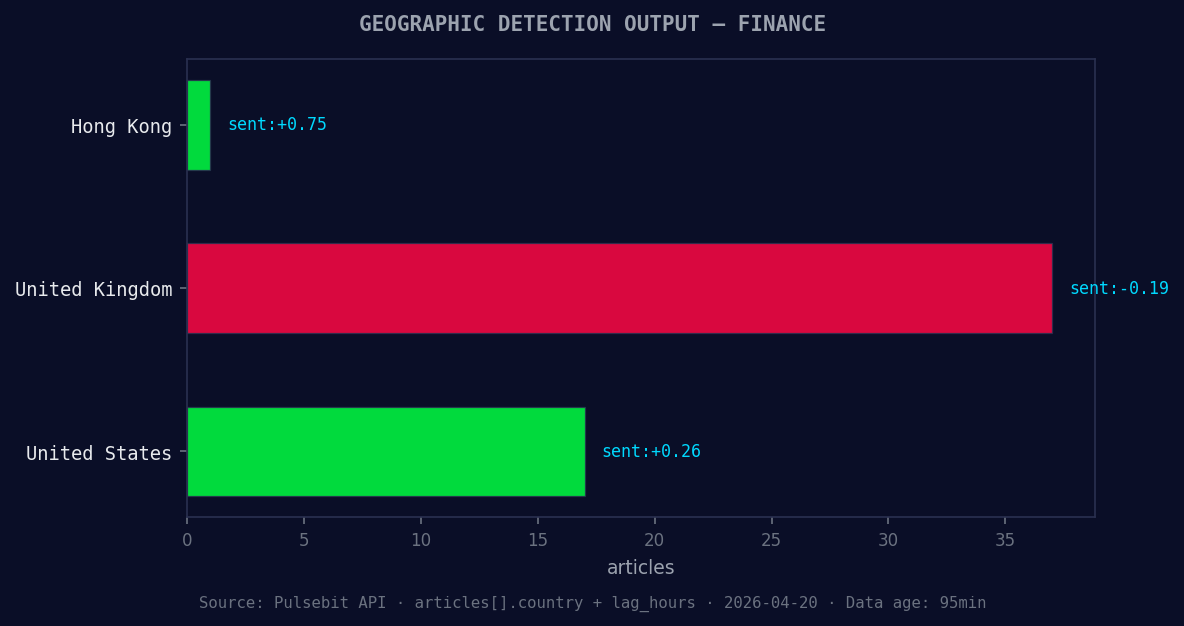
*Geographic detection output for finance. Hong Kong leads with 1 articles and sentiment +0.75. Source: Pulsebit /news_recent geographic fields.*
# Meta-sentiment moment
cluster_reason = "Clustered by shared themes: students, 'huge, relief', given, loans."
sentiment_response = requests.post('https://api.pulsebit.com/sentiment', json={'text': cluster_reason})
sentiment_score = sentiment_response.json()
print(f"Fetched {len(articles)} articles with sentiment score: {sentiment_score}")
In this snippet, we first get articles related to finance, filtering by the English language. Next, we feed our cluster reason string to the sentiment endpoint, allowing us to score the narrative framing itself. This is crucial because it helps us understand not just the sentiment but the context behind it.
Three Builds Tonight
Geographic Origin Filter: Extend the query to capture the sentiment around finance in specific regions. Use the geographic origin filter to analyze sentiment based on "lang": "en". This helps refine your insights further, particularly useful if you're focusing on specific markets.
Meta-Sentiment Loop: After identifying the spike, run the cluster reason string through the sentiment API. This helps validate the context around the spike. For instance, use the input: "Clustered by shared themes: students, 'huge, relief', given, loans." This allows you to gauge how narratives are shaping sentiment.
Forming Themes Analysis: Focus on the emerging themes around the finance sector, where we see a momentum of +0.00. You can create a real-time alert system that triggers when sentiment scores around finance and related topics (like Google and student loan relief) reach a specific threshold. This will keep you ahead of mainstream discussions.
Get Started
Dive into our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste this code and run it in under 10 minutes to start capturing these insights. Don't let your pipeline lag behind—stay ahead of the trends that matter.

Top comments (0)