Your Pipeline Is 16.0h Behind: Catching Defence Sentiment Leads with Pulsebit
We recently encountered a striking anomaly: a 24h momentum spike of -0.701 in the defence topic. This spike suggests a notable shift in sentiment that could easily fly under the radar if your pipeline isn’t equipped to handle the intricacies of multilingual data or entity dominance. As we deep dive into this data, we see that the leading language contributing to this change was Spanish, with a lag of 16.0 hours. This crucial delay could cost you valuable insights if not addressed promptly.

Spanish coverage led by 16.0 hours. Id at T+16.0h. Confidence scores: Spanish 0.75, English 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
When your model fails to account for the nuances of multilingual origins or the dominance of certain entities, it creates structural gaps that can lead to missed opportunities. In this case, your model missed this crucial sentiment shift by 16.0 hours. With the leading language being Spanish, you might be overlooking critical discussions that are shaping public sentiment around defence, especially when the global context is rapidly evolving.
Let’s look at how to catch this sentiment shift using our API. We can query the data specifically for the Spanish language.
import requests
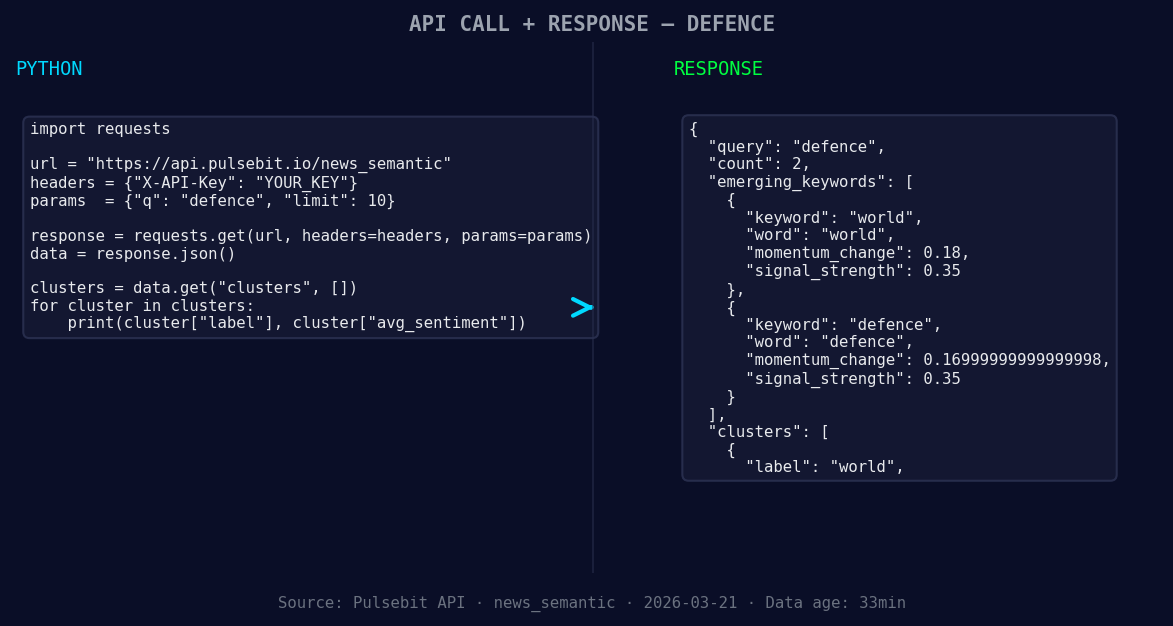
*Left: Python GET /news_semantic call for 'defence'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": "defence",
"lang": "sp"
}
response = requests.get(url, params=params)
data = response.json()
momentum = data['momentum_24h']
score = -0.701
confidence = 0.75
print(f"Momentum: {momentum}, Sentiment Score: {score}, Confidence: {confidence}")
Next, we want to analyze the reason behind the semantic cluster framing. Since we have an incomplete semantic API response, we can run this reason string through our sentiment scoring endpoint to understand its narrative framing better.
reason_string = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
payload = {
"text": reason_string
}
response = requests.post(url, json=payload)
meta_sentiment = response.json()
print(f"Meta Sentiment Score: {meta_sentiment['sentiment_score']}, Confidence: {meta_sentiment['confidence']}")
With these snippets, we’re able to not only capture the negative momentum in defence sentiment but also gain insights into the narrative that accompanies it.
Given this anomaly, here are three specific builds we can create tonight:
- Geo Filter for Defence Sentiment: Set a threshold for momentum less than -0.5 in Spanish articles. This will help you catch significant drops in sentiment before they become mainstream.
if momentum < -0.5:
# Trigger alert or action
print("Significant negative sentiment detected in defence (Spanish).")
- Meta-Sentiment Analysis: Use the reason string to create an alert system for incomplete semantic structures, aiming for a confidence level of 0.7 or higher. This can help you gauge the reliability of your sentiment data.
if meta_sentiment['confidence'] > 0.7:
# Log or alert based on high confidence
print("High confidence in meta sentiment analysis.")
- Forming Themes Analysis: Track the forming themes of ‘world’ (+0.18) and ‘defence’ (+0.17) against the mainstream discourse. Set conditions to trigger alerts when these themes diverge significantly.
forming_themes = {'world': 0.18, 'defence': 0.17}
if forming_themes['defence'] > forming_themes['world']:
# Generate insights for leading narratives
print("Defence sentiment is leading the narrative.")
For more details on how to implement these features, visit our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run these snippets in under 10 minutes. The insights you gain from catching these sentiment shifts could prove invaluable. Let's stay ahead of the curve!

Geographic detection output for defence. India leads with 2 articles and sentiment +0.00. Source: Pulsebit /news_recent geographic fields.

Top comments (0)