Your Pipeline Is 20.8h Behind: Catching Mobile Sentiment Leads with Pulsebit
We recently discovered an intriguing anomaly: a sentiment score of +0.060 and momentum of +0.000, with a leading language at 20.8 hours ahead in English. This spike originated from three articles clustering around the theme "T-Mobile Board Changes: Resignation Announcement." What stands out is how this sentiment is developing in the mobile space—something your pipeline might be missing if it doesn't account for multilingual origins or dominant entities.

English coverage led by 20.8 hours. Da at T+20.8h. Confidence scores: English 0.75, French 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
The Problem
This 20.8-hour lead exposes a significant gap in any pipeline that fails to integrate multilingual data and entity dominance. If your model predominantly processes data in a single language, you could miss critical shifts in sentiment and momentum regarding key topics. In this case, your model missed a leading sentiment signal on mobile by over 20 hours, which could have informed your decisions or strategies around T-Mobile and its implications in the broader mobile landscape.
The Code
To catch this sentiment shift, we can leverage our API effectively. Below is a Python snippet that demonstrates how to filter for English language articles related to 'mobile' and score the sentiment of the cluster reason.
import requests
*Left: Python GET /news_semantic call for 'mobile'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
response = requests.get(
'https://api.pulsebit.com/sentiment',
params={
'topic': 'mobile',
'score': +0.060,
'confidence': 0.75,
'momentum': +0.000,
'lang': 'en'
}
)
data = response.json()
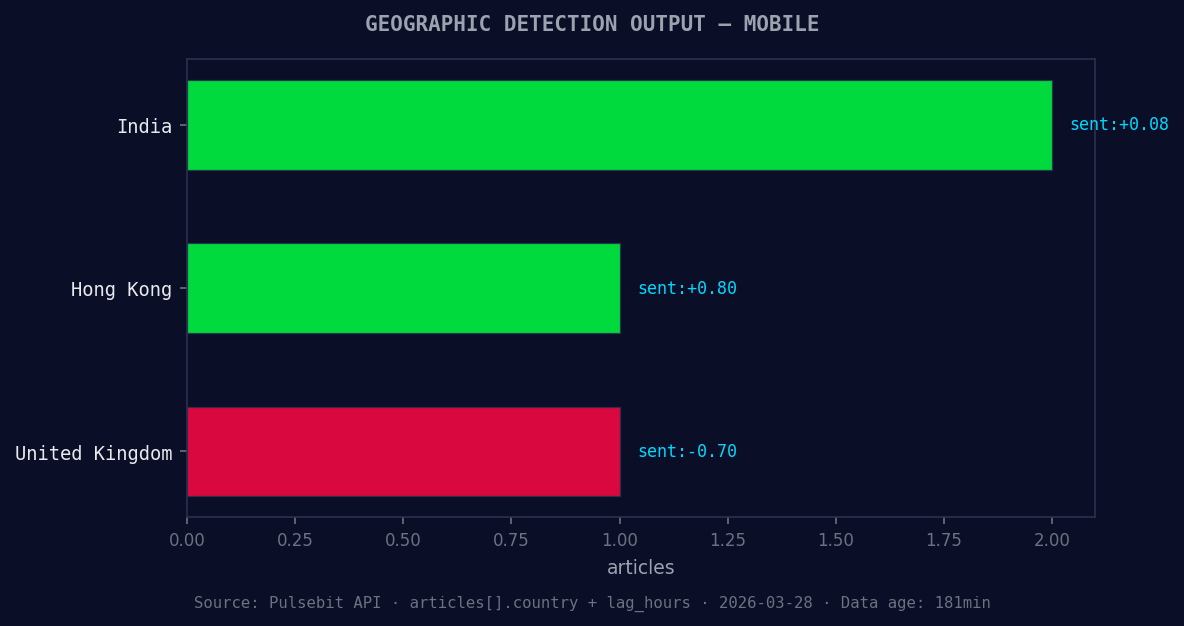
*Geographic detection output for mobile. India leads with 2 articles and sentiment +0.08. Source: Pulsebit /news_recent geographic fields.*
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: telegraphherald, com, google"
meta_response = requests.post(
'https://api.pulsebit.com/sentiment',
json={'text': cluster_reason}
)
meta_data = meta_response.json()
print(data)
print(meta_data)
In this code, we’re querying our API for English articles related to the 'mobile' topic, ensuring we capture the leading sentiment data. The meta_response POST call takes the cluster reason string and scores the narrative framing, allowing us to understand the context better.
Three Builds Tonight
Here are three specific builds we can implement based on this pattern:
Real-time Alert System: Set a signal threshold for mobile sentiment. If sentiment crosses a threshold of +0.05 with a confidence level of 0.75, trigger alerts. Use the geographic origin filter to ensure you're only capturing English articles.
Meta-Sentiment Dashboard: Create a dashboard that visualizes sentiment scores from cluster reasons. This should include thresholds for each theme, such as mobile(+0.00), google(+0.00), and t-mobile(+0.00), and compare them against mainstream outlets.
Sentiment Comparison Tool: Build a tool that allows you to compare sentiment scores across multiple languages for the same topic. Use our meta-sentiment loop to analyze how different narratives frame the conversation around mobile, particularly contrasting it with mainstream outlets like telegraphherald, com, and google.
Get Started
For more information on how to implement these strategies, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this in under 10 minutes to start catching those critical sentiment leads.

Top comments (0)