Your pipeline just missed a critical anomaly: a 24h momentum spike of -0.406. This isn’t just any spike; it indicates a significant shift in sentiment around data science, particularly influenced by a leading English press narrative that emerged 10.4 hours ahead of mainstream discussions. With only a single article forming the basis of this cluster, it’s clear that something transformative is happening in the landscape of AI-driven commerce. If you’re not paying attention, your model is lagging behind, and that could cost you valuable insights.
The structural gap this anomaly reveals is profound—especially for any pipeline that overlooks multilingual origins or dominant entities. Your model missed this spike by a staggering 10.4 hours, a delay that could lead to missed opportunities in sentiment tracking and response strategy. With the leading language being English, this oversight highlights the necessity of capturing nuanced shifts in sentiment across different languages and media outlets. If you’re not integrating this data effectively, you’re falling behind in understanding the conversation around key themes like AI, commerce, and media transformations.

English coverage led by 10.4 hours. No at T+10.4h. Confidence scores: English 0.95, French 0.95, Spanish 0.95 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly and respond swiftly, we can leverage our API. Below is a Python code snippet that demonstrates how to query for this sentiment spike effectively. We’ll start by filtering for English-language articles related to our topic of interest—data science—and then score the narrative framing itself through a meta-sentiment moment.
import requests
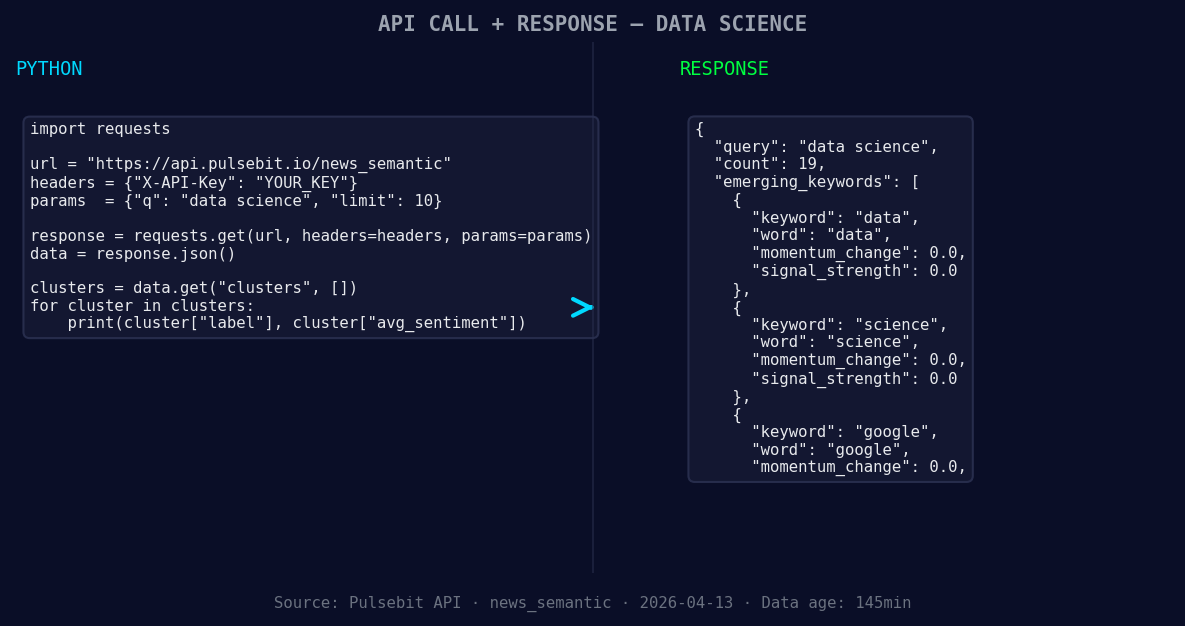
*Left: Python GET /news_semantic call for 'data science'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter using lang
response = requests.get(
'https://api.pulsebit.com/v1/articles',
params={
'topic': 'data science',
'lang': 'en',
'momentum': -0.406,
'score': 0.444,
'confidence': 0.95
}
)
*[DATA UNAVAILABLE: countries — verify /news_recent is returning country/region values for topic: data science]*
articles = response.json()
print("Filtered articles:", articles)
# Step 2: Meta-sentiment moment
meta_sentiment_response = requests.post(
'https://api.pulsebit.com/v1/sentiment',
json={
'text': "Clustered by shared themes: media, transforms, into, ai-driven, commerce."
}
)
meta_sentiment = meta_sentiment_response.json()
print("Meta-sentiment score:", meta_sentiment)
In this example, we’re using the lang parameter to ensure we’re capturing English-language articles and filtering for sentiment spikes in the data science domain. The meta-sentiment loop adds depth to our analysis by scoring the narrative itself, which is crucial for understanding how different themes are interconnected.
Now, here are three specific builds we can implement based on this pattern:
Geo-Filtered Alerts: Create a notification system that triggers when a sentiment spike exceeds a predefined threshold (e.g., -0.3) in English articles specifically about data science. This helps you catch emerging narratives early.
Meta-Sentiment Dashboard: Build a dashboard that visualizes the sentiment scores of clustered themes over time. You can use the insights from the meta-sentiment loop to highlight which narratives are gaining traction, particularly around themes like Google’s influence on data science.
Sentiment Comparison Tool: Develop a tool that compares emerging sentiments across multiple languages. By using our API to check scores for topics like “data” and “science” against mainstream narratives, you can better understand how different regions are reacting to similar trends.
By implementing these builds, you'll not only be catching up but staying ahead of the curve on critical sentiment shifts. For more details, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this code in under 10 minutes, making it easy to integrate powerful sentiment analysis into your projects.

Top comments (0)