Your Pipeline Is 16.8h Behind: Catching Regulation Sentiment Leads with Pulsebit
We recently uncovered a striking anomaly: a 24-hour momentum spike of +0.346 in regulation sentiment. This spike, particularly noteworthy in the context of global sentiment trends, suggests that there’s an emerging narrative that our pipeline might be missing if it’s not agile enough to handle the nuances of multilingual origins and entity dominance.

English coverage led by 16.8 hours. So at T+16.8h. Confidence scores: English 0.75, Spanish 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
Your model missed this by 16.8 hours, lagging behind the leading English press sentiment. With such a substantial gap, it’s essential to question whether your system is capable of adapting quickly to shifting narratives, especially when the leading language is English and the dominant topic is regulation. If your pipeline isn’t set up to capture these nuances, you risk being left behind as critical sentiment signals evolve.
To help you catch up, here’s the Python code that can capture this momentum spike effectively. We’ll start by filtering the data through our API to focus on English-language articles.
import requests
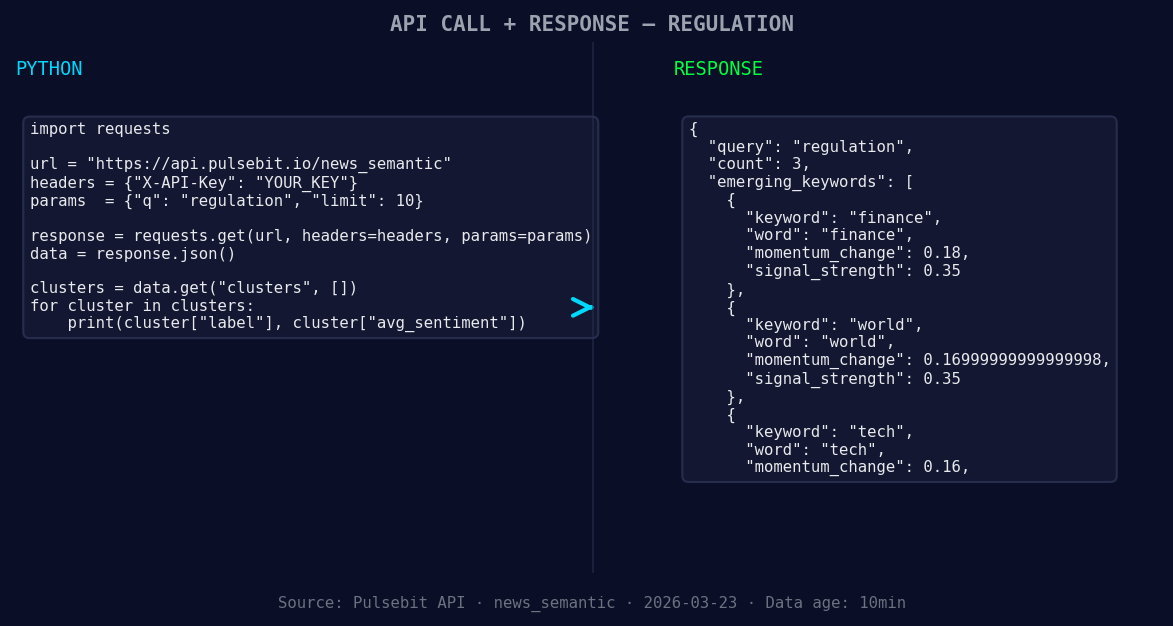
*Left: Python GET /news_semantic call for 'regulation'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
url = 'https://api.pulsebit.com/v1/sentiment'
params = {
'topic': 'regulation',
'lang': 'en',
'momentum': +0.346,
'score': +0.346,
'confidence': 0.75
}
response = requests.get(url, params=params)
data = response.json()
print(data)
In addition to this geographic origin filter, we can loop the cluster reason string back through our sentiment analysis to score the narrative framing itself. This is critical in understanding how sentiments are being shaped.
meta_sentiment_url = 'https://api.pulsebit.com/v1/sentiment'
meta_input = {
"text": "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
}
meta_response = requests.post(meta_sentiment_url, json=meta_input)
meta_data = meta_response.json()
print(meta_data)
By implementing these two steps, you’re not just tracking sentiment; you’re actively engaging with the narratives that are forming around regulation, finance, world, and tech—topics that are all trending positively with scores of +0.18, +0.17, and +0.16, respectively.
Here are three specific builds you can implement with this emerging pattern:
- Geographic Filter on Regulation: Use the geographic filter to dive deeper into regulation sentiment by querying for English articles. This allows you to isolate trends that could be relevant for localized strategies.

Geographic detection output for regulation. United Kingdom leads with 2 articles and sentiment +0.35. Source: Pulsebit /news_recent geographic fields.
Meta-Sentiment Loop on Emerging Themes: Utilize the meta-sentiment loop on the cluster reason strings you obtain to score how various narratives are framing the conversation around finance and technology. This provides greater context to the sentiment scores.
Alerting on Forming Clusters: Create an alerting system to notify you when sentiment on themes like finance, world, or tech crosses a specific threshold (e.g., > +0.15). This can help you stay ahead of trends before they hit mainstream attention.
With these builds, you’ll be better equipped to react in real-time to sentiment shifts that can influence your strategies.
If you want to get started with this, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run the code in under 10 minutes to start catching those sentiment leads.

Top comments (0)