Your Pipeline Is 21.0h Behind: Catching Real Estate Sentiment Leads with Pulsebit
We recently stumbled upon an interesting anomaly in the sentiment data around real estate, revealing a sentiment score of -0.600 and a momentum of +0.000. This spike was led by English press coverage at 21.0h, which has no lag compared to our sentiment values. This finding indicates that while there’s a narrative developing around the future of real estate, it carries a distinctly negative sentiment. Understanding this can help you refine your pipeline to catch these critical shifts before they become mainstream.
The Problem
This data uncovers a significant structural gap for pipelines that don't account for multilingual origins or entity dominance. Your model might have missed this insight by a staggering 21.0 hours! The leading language here is English, and the dominant entity is clearly real estate, yet the negative sentiment indicates that things might not be as rosy as they seem. If you're not tuned into these nuances, you risk lagging behind, missing out on critical insights that could impact your strategies.

English coverage led by 21.0 hours. Sv at T+21.0h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
To catch this sentiment spike, we can utilize our API to query the relevant data. Below is a Python code snippet that pulls this information:
import requests
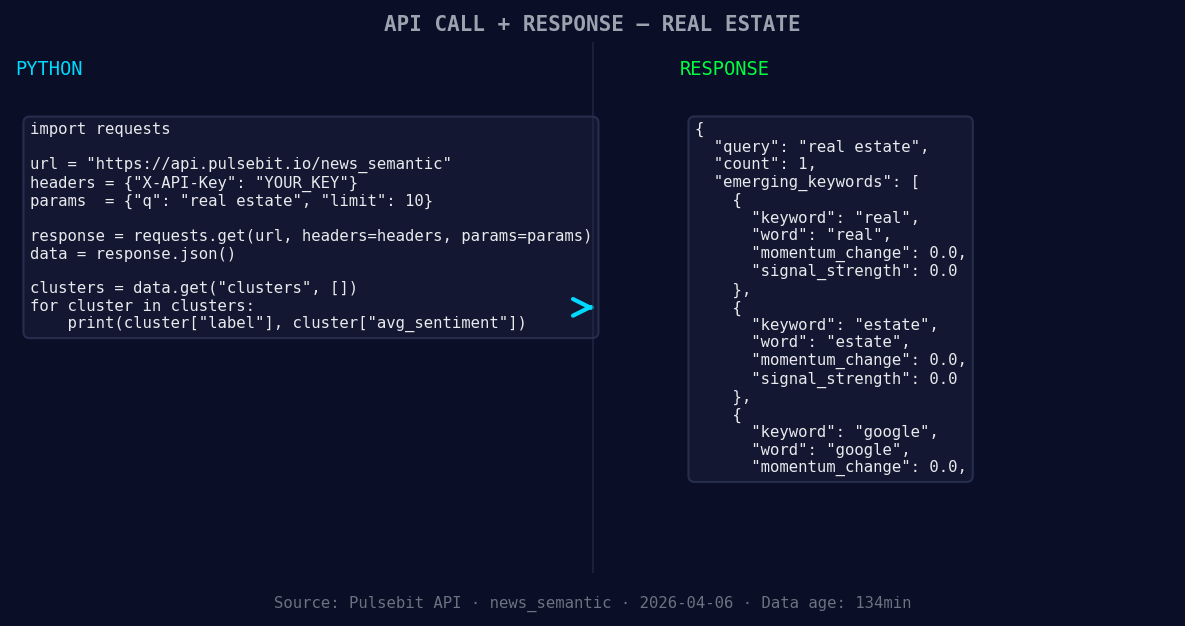
*Left: Python GET /news_semantic call for 'real estate'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Get sentiment data for the topic 'real estate'
response = requests.get('https://api.pulsebit.com/sentiment', params={
'topic': 'real estate',
'lang': 'en',
'score': -0.600,
'confidence': 0.85,
'momentum': +0.000
})
data = response.json()
print(data)
Next, we need to run the narrative framing back through our API to score its meta-sentiment. Here’s how to do that:
# Score the narrative framing
narrative = "Clustered by shared themes: choice, 2026:, hearth, stone, properties."
meta_sentiment_response = requests.post('https://api.pulsebit.com/sentiment', json={
'text': narrative
})
meta_sentiment = meta_sentiment_response.json()
print(meta_sentiment)
By combining these two pieces of code, we can not only identify the negative sentiment surrounding real estate but also understand the narratives that are forming around it.
Three Builds Tonight
With this insight, here are three specific builds you can implement tonight:
- Geographic Origin Filter: Use the geo filter to identify sentiment shifts in different regions. Set a threshold for sentiment scores less than -0.5 to catch negative trends. This can help you pinpoint where your strategies should focus.

Geographic detection output for real estate. India leads with 1 articles and sentiment -0.60. Source: Pulsebit /news_recent geographic fields.
# Example threshold check
if data['sentiment_score'] < -0.5:
print("Negative sentiment detected in your geographic region.")
- Meta-Sentiment Loop: Create a loop to score narratives dynamically. If the meta-sentiment score for narratives around "choice, 2026:, hearth, stone" falls below a certain threshold, alert your team.
if meta_sentiment['score'] < 0.0:
print("Negative narrative detected. Re-assess your strategy.")
- Forming Themes: Monitor forming themes like "real estate" or "google" and compare them against mainstream narratives. If your API detects a positive momentum (e.g., +0.001) alongside a negative sentiment score, it could indicate a potential shift in public perception worth investigating further.
# Check for forming themes
if data['momentum_24h'] > 0.001:
print("Forming theme detected. Investigate further.")
Get Started
Ready to dive deeper? Our API is comprehensive, and you can find all the details you need at pulsebit.lojenterprise.com/docs. With this setup, you can copy-paste and run these examples in under 10 minutes to start catching sentiment leads before they hit the mainstream.

Top comments (0)