Your Pipeline Is 13.3h Behind: Catching Sports Sentiment Leads with Pulsebit
We recently discovered a significant anomaly: a 24h momentum spike of +0.390 in the sports sentiment space. This isn't just a blip; it's a clear signal that something is stirring in the sports narrative, especially when you consider the leading language of this sentiment is English, with a 13.3-hour lead time. If you're not tuned into this shift, your pipeline might be lagging far behind.
When we see a momentum spike like this, it's a red flag for any sentiment pipeline that doesn't account for multilingual origins or entity dominance. Your model missed this by 13.3 hours—an eternity in sentiment analysis. The leading narrative revolves around the themes of "congress," "sports," and "fund," which indicates a powerful intersection of politics and sports that could impact various sectors. If you’re not aware of these emerging trends, you risk missing critical insights that could inform your models and strategies.

English coverage led by 13.3 hours. Ro at T+13.3h. Confidence scores: English 0.90, Spanish 0.90, French 0.90 Source: Pulsebit /sentiment_by_lang.
Here's how we can catch this momentum spike accurately using our API.
import requests
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/sentiment"
params = {
"topic": "sports",
"lang": "en",
}
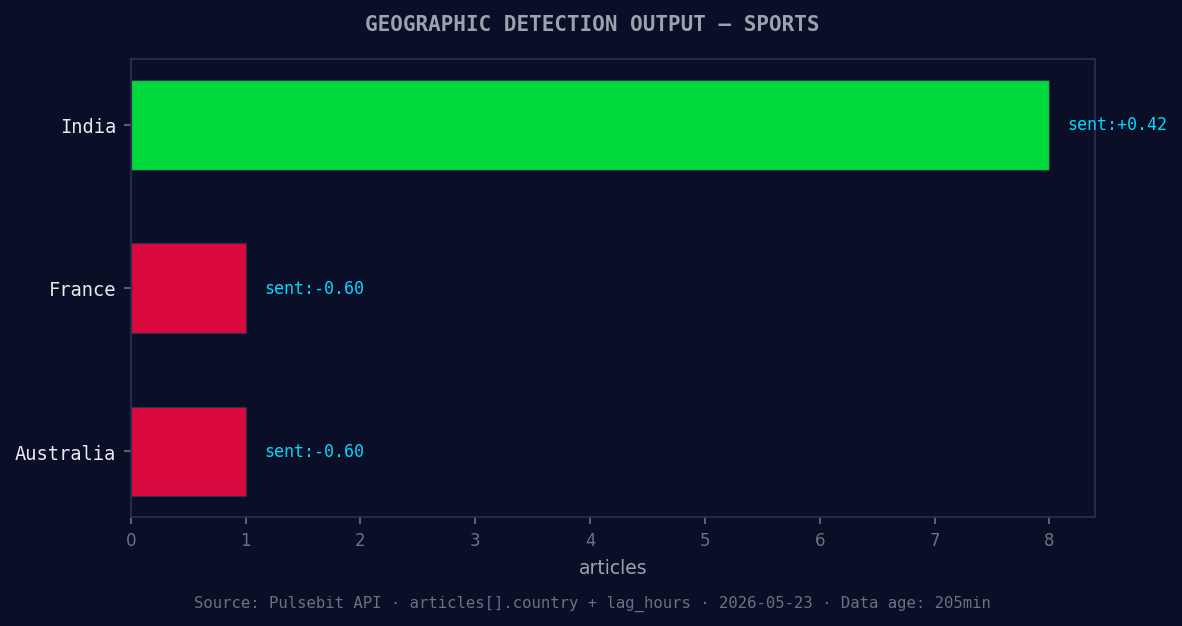
*Geographic detection output for sports. India leads with 8 articles and sentiment +0.42. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
# Example data structure returned
print(data)
# Step 2: Meta-sentiment moment
meta_sentiment_input = "Clustered by shared themes: congress, sports, fund, says, ‘petty."
meta_sentiment_response = requests.post(f"{url}/sentiment", json={"text": meta_sentiment_input})
meta_sentiment_data = meta_sentiment_response.json()
print(meta_sentiment_data)
In this code, we first filter our sentiment analysis by language, focusing on English to ensure we capture the nuances of the dominant narrative. Our API call retrieves sentiment data for the "sports" topic. Then, we run the clustered string back through the sentiment endpoint to assess the framing and sentiment of the narrative itself. This two-step approach gives us a clearer picture of sentiment trends.

Left: Python GET /news_semantic call for 'sports'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
Now, let’s talk builds. Here are three specific integrations you can implement with this data:
Geo-Filtered Alerts: Set up a notification system that triggers when sentiment for "sports" in English spikes above a threshold of +0.390. This keeps you informed of critical changes in sentiment based on geographic origin.
Meta-Sentiment Analysis Dashboard: Create a dashboard that visualizes the meta-sentiment from narratives around sports. Use the cluster reason string to gauge how different themes interact, particularly when narratives like "congress" and "fund" emerge alongside "sports." This can help you identify potential biases or shifts in public opinion.
Dynamic Entity Recognition Model: Build a model that dynamically updates based on real-time sentiment shifts. Use the forming themes (like sports and women's issues) to refine your entity recognition. For example, if the sentiment score is +0.00 for women’s issues but rises in relation to sports, you could flag that for deeper analysis.
For further details and to get started, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy and paste the code provided and run it in under 10 minutes. This is your opportunity to leverage real-time sentiment data and stay ahead of the curve.

Top comments (0)