Your Pipeline Is 28.5h Behind: Catching Business Sentiment Leads with Pulsebit
We just noticed a striking anomaly: a 24h momentum spike of +1.450 in the business topic, particularly led by English press with a 28.5h lead time. This indicates that there's a story brewing about bookstores in India, with the cluster titled "Plot twist: bookstores in India." The dataset shows that while the mainstream narrative is focused on more plot twists in business, there's an emerging conversation that your models might not be capturing in real-time.
The Problem
This situation exposes a significant structural gap in any pipeline that doesn’t account for multilingual origins or dominant entities in sentiment analysis. Your model missed this by 28.5 hours, simply because it wasn't designed to recognize the nuances of evolving narratives. The leading language here is English, but the underlying sentiment is clustered around themes that are distinctly tied to a rising business interest in bookstores in India. If you're not tracking these shifts, you’re operating with outdated information.

English coverage led by 28.5 hours. No at T+28.5h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
Let’s dive into how we can catch this anomaly using our API. Below is the Python code that queries for the relevant data and scores the sentiment of the narrative itself.
import requests
*Left: Python GET /news_semantic call for 'business'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": "business",
"lang": "en",
}
response = requests.get(url, params=params)
data = response.json()
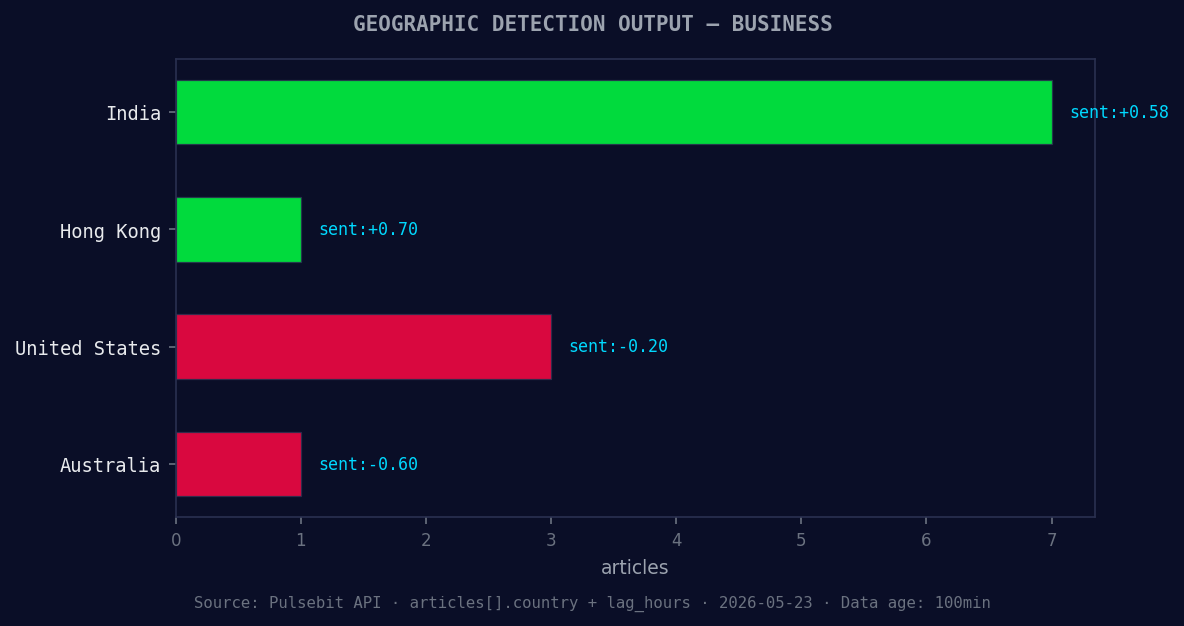
*Geographic detection output for business. India leads with 7 articles and sentiment +0.58. Source: Pulsebit /news_recent geographic fields.*
# Output the main data
print("Momentum:", data['momentum_24h'])
print("Signal Strength:", data['signal_strength'])
# Step 2: Meta-sentiment moment
narrative = "Clustered by shared themes: more, plot, twist:, bookstores, india."
sentiment_response = requests.post(url, json={"input": narrative})
sentiment_data = sentiment_response.json()
# Output the sentiment score
print("Narrative Sentiment Score:", sentiment_data['sentiment_score'])
In this code, we first filter the articles by the English language to pinpoint sentiment specifically around the business topic. We then run the narrative about the clustered themes back through our sentiment scoring endpoint, allowing us to evaluate how the framing itself impacts the overall sentiment.
Three Builds Tonight
Here are three specific builds we can set up with this pattern:
Business Momentum Tracker: Create a signal that alerts you whenever the business topic's momentum exceeds a threshold of +1.0. Use the geographic origin filter to ensure you’re only capturing relevant English-language sources.
Meta-Sentiment Analyzer: Develop a routine that automatically scores narratives clustered around keywords like "business," "plot," and "twist." This could involve tracking articles over a rolling 24-hour window, providing a real-time sentiment score for emerging stories.
Gap Analysis Dashboard: Build a dashboard that visualizes the growing gap between forming narratives and mainstream topics, specifically focusing on the sentiment differences for topics like business versus the plot twists in less mainstream themes. This will help you identify not just what's trending, but what’s trending faster than you can react.
Get Started
Ready to catch these insights yourself? Visit pulsebit.lojenterprise.com/docs. You can copy, paste, and run the above code in under 10 minutes to start tracking sentiment shifts that your models might be missing.

Top comments (0)