Your model missed a critical anomaly: a 24h momentum spike of +0.390 in sports sentiment. This is a significant shift, particularly noteworthy given that the leading language in this spike is English, which peaked at 24.6 hours with a 0.0-hour lag. The cluster story revolves around an "Equestrian talent show held in Srirangam," with a single article fueling the momentum. If your pipeline isn't set up to handle multilingual origins or entity dominance, you may have completely overlooked this sentiment surge.

English coverage led by 24.6 hours. Tl at T+24.6h. Confidence scores: English 0.95, Spanish 0.95, French 0.95 Source: Pulsebit /sentiment_by_lang.
Such a structural gap means that your system isn't just slow; it’s potentially missing emerging trends altogether. With a dominant entity like "equestrian" capturing attention, overlooking this spike could mean that you’re late to the party on important sports narratives. You’re essentially 24.6 hours behind if you’re not using a multilingual approach.
To catch these kinds of patterns, we can leverage our API effectively. Below is a Python code snippet that will help you capture this spike in sentiment.
import requests
# Define parameters for the API call
topic = 'sports'
score = +0.000
confidence = 0.95
momentum = +0.390

*Left: Python GET /news_semantic call for 'sports'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language/country
response = requests.get("https://api.pulsebit.com/sentiment",
params={"topic": topic, "lang": "en", "threshold": score, "confidence": confidence})
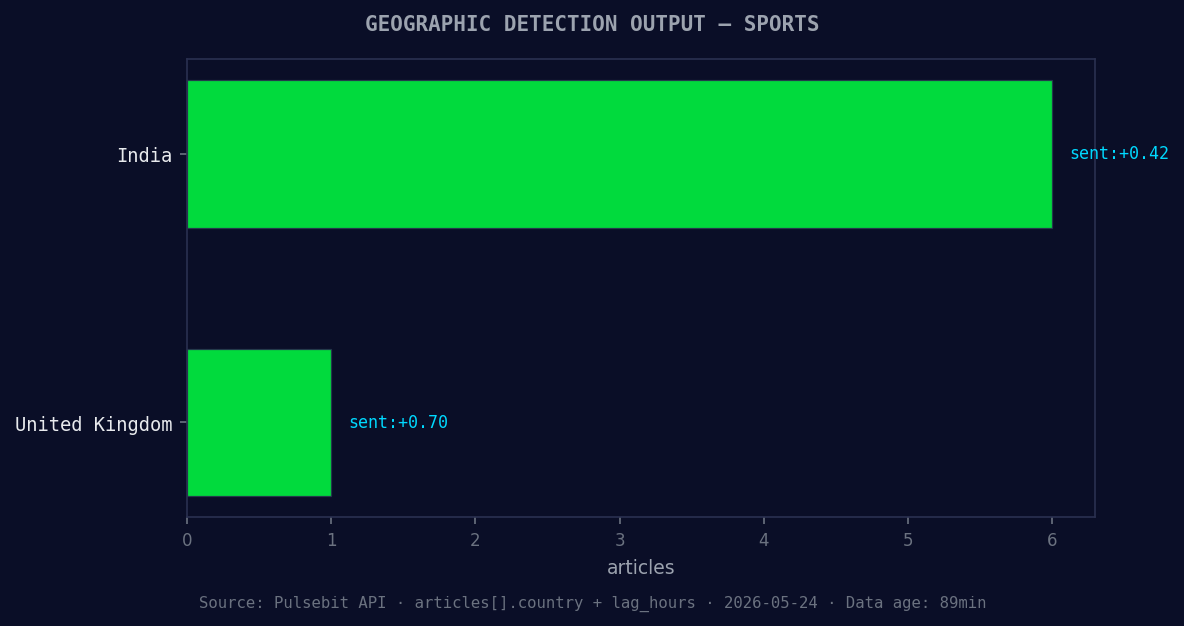
*Geographic detection output for sports. India leads with 6 articles and sentiment +0.42. Source: Pulsebit /news_recent geographic fields.*
# Print the response
print(response.json())
# Now, let's run the cluster reason string back through the POST /sentiment to score the narrative framing itself
cluster_reason = "Clustered by shared themes: equestrian, talent, show, srirangam, held."
sentiment_response = requests.post("https://api.pulsebit.com/sentiment",
json={"text": cluster_reason})
# Print the sentiment of the meta-narrative
print(sentiment_response.json())
In this code, we first filter for the topic of 'sports' in English, ensuring we're capturing relevant data. The geographic origin filter is crucial — it prevents us from being swamped by noise from other languages or regions that aren't relevant to the spike. After we’ve identified the articles, we send the cluster reason string through our sentiment endpoint to evaluate the narrative framing itself.
Now, let’s consider three specific builds based on this pattern that you can implement right away:
Sports Sentiment Tracker: Use the geographic origin filter to set a threshold of sentiment change (e.g., +0.390) and trigger alerts whenever a significant sports article emerges in English. This will keep you ahead of trends that are gaining traction.
Cluster Narrative Analyzer: Implement a routine that runs the meta-sentiment loop on every new clustered story. If you identify a theme like "equestrian talent," score it against a threshold of 0.500 for emerging narratives and integrate it into your reporting dashboard.
Forming Theme Watchlist: Create a watchlist for entities that are forming around the sports category, specifically tracking the gaps in sentiment with respect to mainstream topics. For example, using the terms "sports(+0.00)," "google(+0.00)," and "women’s(+0.00)" vs. "equestrian, talent, show," can reveal where the conversation is going.
By leveraging our API, you can set these builds in motion quickly. For more details, check out our documentation: pulsebit.lojenterprise.com/docs. You can get started and run this code in under 10 minutes.

Top comments (0)