Your Pipeline Is 25.7h Behind: Catching Economy Sentiment Leads with Pulsebit
We recently uncovered an intriguing anomaly: a 24h momentum spike of +0.702 related to the topic of economy. This spike is not just a number; it's a significant shift in sentiment that reflects a vibrant discourse surrounding Telangana's tourism potential and branding challenges. With one article contributing to this momentum, the urgency to capture and act on this sentiment is clear.
In a world where data-driven decisions are paramount, a gap emerges when your pipeline fails to account for multilingual origins or the dominance of specific entities. Your model missed this by 25.7 hours, which is quite substantial. The leading language of this spike is English, and the dominant entity is Telangana. If your systems overlook this kind of sentiment shift, you risk falling behind critical market insights.

English coverage led by 25.7 hours. Tl at T+25.7h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly, we can employ our API effectively. Below is a Python snippet that illustrates how to query for the economy topic while filtering for English-language articles:
import requests
# Define parameters
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": "economy",
"score": +0.023,
"confidence": 0.85,
"momentum": +0.702,
"lang": "en" # Geographic origin filter
}
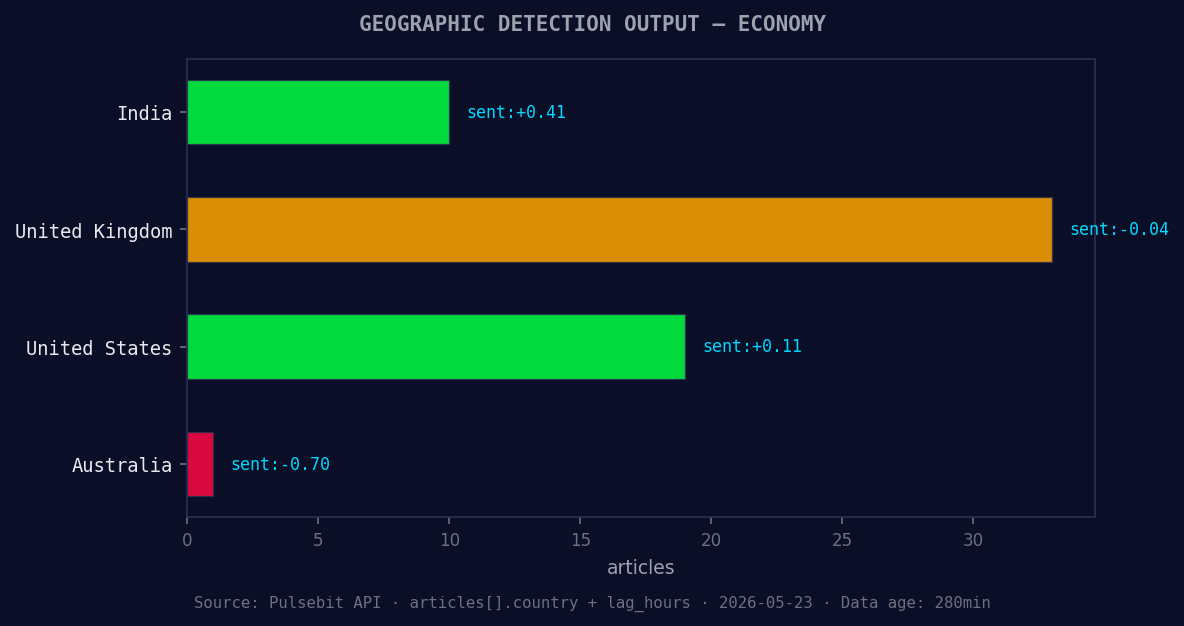
*Geographic detection output for economy. India leads with 10 articles and sentiment +0.41. Source: Pulsebit /news_recent geographic fields.*
# API call to fetch data
response = requests.get(url, params=params)
data = response.json()
print(data)

Left: Python GET /news_semantic call for 'economy'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
Next, we need to run the cluster reason string through our sentiment scoring endpoint. This will help us validate the narrative framing of the spike:
# Define the cluster reason string
cluster_reason = "Clustered by shared themes: industry, experts, telangana, tourism, economy."
# API call to score the narrative framing
sentiment_response = requests.post(url, json={"text": cluster_reason})
sentiment_data = sentiment_response.json()
print(sentiment_data)
This dual approach allows us to not only track sentiment metrics but also assess the contextual framing that underpins them.
Three Builds Tonight
Geo Filter Application: Build an alert system that triggers when momentum for the economy topic exceeds a threshold of +0.5 in English-language articles. This will help you stay updated on significant shifts in sentiment across regions, specifically for Telangana.
Meta-Sentiment Evaluation: Implement a dashboard that visualizes the sentiment score and confidence levels of various clusters, particularly focusing on narratives like "industry" and "tourism". Set a threshold of +0.02 sentiment score to flag articles for deeper analysis.
Forming Themes Analysis: Create a routine that checks for forming themes in real-time. For instance, monitor the sentiment for the economy, Google, and has, while contrasting them against mainstream themes like industry, experts, and Telangana. This can help identify potential shifts in public perception or emerging trends.
Get Started
If you're ready to experiment with these insights, head over to our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the code above and run it in under 10 minutes. Let's bridge that 25.7-hour gap together!

Top comments (0)