Your pipeline just missed a significant anomaly: a 24-hour momentum spike of +0.867. This spike indicates a notable shift in sentiment surrounding the topic of "world," driven largely by a developing narrative around Tamils and their cultural representation in a three-day event in Toronto. As developers, it's vital for us to catch these spikes quickly, especially when they're tied to specific events or cultural discussions.
If your pipeline isn't designed to handle multilingual origins or recognize dominant entities, you might be lagging behind by 27.2 hours. In this case, the leading language is English, with the sentiment emerging from press coverage about a gathering focused on Tamil culture. The failure to adapt to these nuances results in missed opportunities for timely insights, leaving your model squarely out of touch with evolving narratives.

English coverage led by 27.2 hours. Et at T+27.2h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly, we need to query our data effectively. Below is the Python code that utilizes our API to filter by language and assess sentiment. We're looking specifically for insights related to the topic "world" with the following parameters: score=+0.013, confidence=0.85, momentum=+0.867.
import requests
*Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'world'
score = +0.013
confidence = 0.85
momentum = +0.867
lang = 'en'
# Geographic origin filter
response = requests.get(
f'https://api.pulsebit.com/v1/sentiment?topic={topic}&lang={lang}&momentum={momentum}'
)
data = response.json()
print(data)
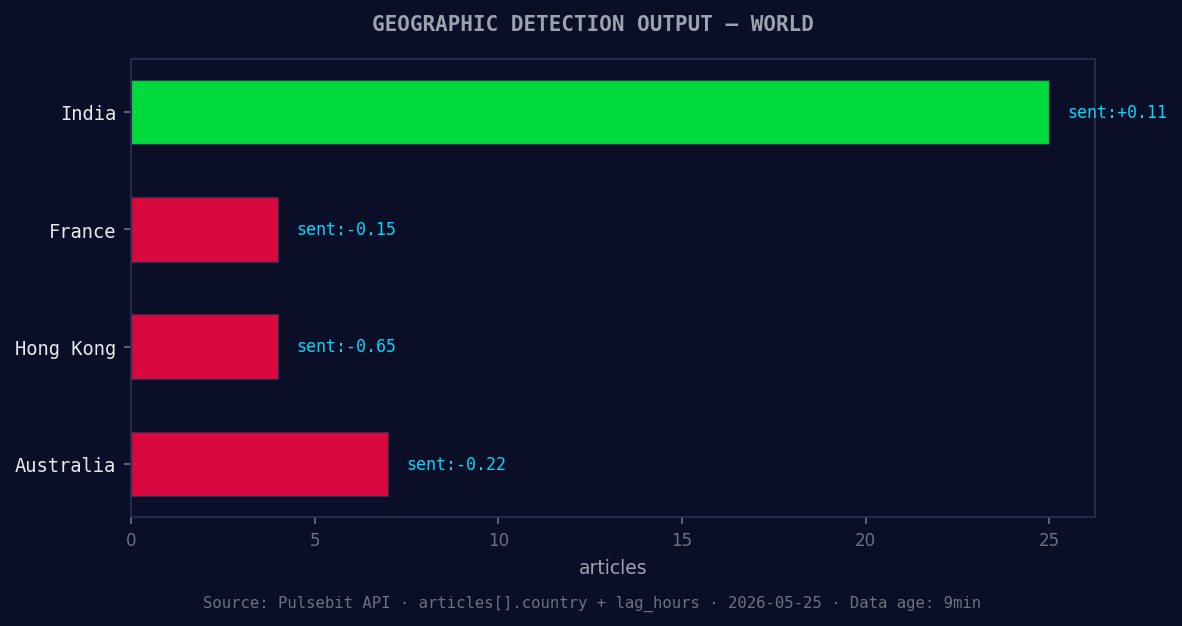
*Geographic detection output for world. India leads with 25 articles and sentiment +0.11. Source: Pulsebit /news_recent geographic fields.*
# Meta-sentiment moment
cluster_reason = "Clustered by shared themes: three-day, toronto, tamils, classical, tamil."
sentiment_response = requests.post(
'https://api.pulsebit.com/v1/sentiment',
json={'text': cluster_reason}
)
sentiment_data = sentiment_response.json()
print(sentiment_data)
In the first part, we filter our data for the "world" topic with the language set to English, ensuring we capture the relevant sentiments from the appropriate demographic. The second part sends the cluster reason back through our sentiment endpoint to score the narrative itself. This is crucial as it allows us to assess the framing of the story that’s emerging around this cultural event.
Here are three specific builds we can create with this pattern:
Sentiment Tracking for Cultural Events: Set a signal threshold of +0.867 on momentum for topics related to cultural gatherings. This can alert you when significant sentiment changes occur, particularly for events like the three-day meeting in Toronto.
Geo-Filtered Alerts: Create a geo-filtered alert system that triggers when sentiment spikes in specific regions. For example, set a threshold for the "world" topic that captures sentiment from English-language sources in Canada, particularly around discussions of Tamils.
Meta-Sentiment Analysis Dashboard: Build a dashboard that visualizes meta-sentiment scores for clustered narratives like the aforementioned story. This can utilize scores from the sentiment API to provide insights into how narratives are framed over time, especially for emerging themes like "google" and "cup" versus mainstream discussions.
You can get started with our API documentation at pulsebit.lojenterprise.com/docs. With the above code, you can copy-paste and run this in under 10 minutes. Don't let your models fall behind—stay ahead of the curve by catching these vital sentiment shifts!

Top comments (0)