Your pipeline is 23.8 hours behind: catching inflation sentiment leads with Pulsebit
We just noticed a compelling anomaly in our sentiment data: a 24-hour momentum spike of +0.532 related to inflation. This spike indicates a rising sentiment, which is particularly significant given the recent developments in the CNG market. The leading language driving this narrative is English, making up 23.8 hours of the 24-hour window. The cluster story reads, “Watch: CNG at ₹83/kg: Auto, Taxi drivers furious over repeated CNG price hikes.” This is an important moment that we shouldn't overlook.
The problem here lies in the structural gaps of pipelines that don't account for multilingual origins or entity dominance. If your model isn't designed to handle these factors, you could be missing critical insights. In this case, your model missed this spike by 23.8 hours. With the leading entity focused on CNG and the dominant language being English, any analysis without these considerations may lead to missed opportunities or misinterpretations of the sentiment landscape.

English coverage led by 23.8 hours. No at T+23.8h. Confidence scores: English 0.85, Spanish 0.85, Id 0.85 Source: Pulsebit /sentiment_by_lang.
Let’s dive into the code that can catch this momentum spike effectively:
import requests
# Define parameters
topic = 'inflation'
score = -0.222
confidence = 0.85
momentum = +0.532
# Geographic origin filter
url = "https://api.pulsebit.com/sentiment"
params = {
"topic": topic,
"lang": "en",
"score": score,
"confidence": confidence,
"momentum": momentum
}
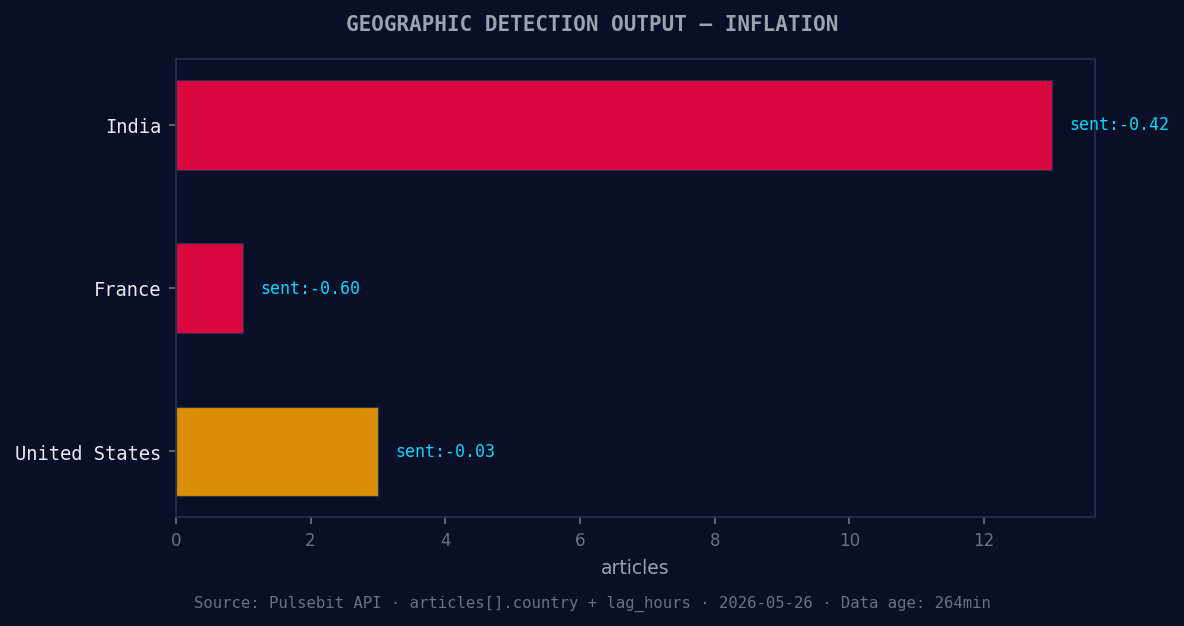
*Geographic detection output for inflation. India leads with 13 articles and sentiment -0.42. Source: Pulsebit /news_recent geographic fields.*
# Make the API call
response = requests.get(url, params=params)
data = response.json()
print(data)

Left: Python GET /news_semantic call for 'inflation'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
Next, let’s analyze the narrative framing itself. We need to run the cluster reason string back through our sentiment analyzer:
# Meta-sentiment moment
cluster_reason = "Clustered by shared themes: cng, auto, taxi, drivers, watch:."
sentiment_url = "https://api.pulsebit.com/sentiment"
meta_response = requests.post(sentiment_url, json={"text": cluster_reason})
meta_data = meta_response.json()
print(meta_data)
This code does two things: it filters the sentiment data based on geographic origin and evaluates the cluster story to understand how the narrative is being framed. This dual approach allows us to capture the nuances of sentiment and its implications more effectively.
Now that we have a solid understanding of how to capture this spike, here are three specific builds we can implement:
Signal Detection with Geo Filter: Set up a real-time alert system that triggers when momentum for inflation crosses a threshold of +0.5 in English-speaking regions. Use the geo filter to refine your data collection, ensuring you catch movements in sentiment before they become mainstream.
Meta-Sentiment Analysis Loop: Create a dashboard that visualizes the sentiment scores of clustered narratives. Every time a new article is processed, run the related themes through the meta-sentiment loop. For instance, running the cluster reason of “CNG, auto, taxi” will help you identify rising narratives that traditional models might overlook.
Forming Themes Tracker: Develop a tracking system for forming themes like inflation, Google, and markets versus mainstream topics like CNG and auto. Set alerts for when these themes show significant divergence, suggesting a potential sentiment shift that could impact decision-making.
We encourage you to explore these insights further at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can copy-paste and run these examples in under 10 minutes, giving your pipeline the edge it needs to stay ahead of the curve.

Top comments (0)