Your pipeline just missed a 24h momentum spike of -0.362 surrounding tech startups. This anomaly is intriguing because it reveals that sentiment is shifting away from the usually optimistic narrative that surrounds emerging technology. When we dive deeper, we see that English-language articles are leading the sentiment narrative with a lag of 25.8 hours against German articles. This indicates a significant delay in your pipeline when handling multilingual content and entity dominance. If your model isn't tuned to capture these shifts, you might be left behind—your model missed this by 25.8 hours.

English coverage led by 25.8 hours. German at T+25.8h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
This delay in sentiment analysis can severely impact your ability to gauge emerging trends. The leading narrative around startups, particularly in English-speaking regions, suggests a declining interest or confidence in tech investments. If your pipeline isn't designed to handle these nuances—especially the multilingual origins and the dominance of certain entities—you risk making decisions based on outdated or misleading information.
Here’s how you can catch this anomaly using our API. We’ll start by filtering for English-language articles about startups. The following Python code accomplishes this:
import requests
*Left: Python GET /news_semantic call for 'startups'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'startups'
score = +0.375
confidence = 0.85
momentum = -0.362
language = 'en'
# Geographic origin filter: query by language
response = requests.get(f'https://api.pulsebit.com/articles?topic={topic}&lang={language}')
articles = response.json()
# Check if we have articles
if articles:
print("Articles retrieved: ", len(articles))
# Run the cluster reason string back through the sentiment API
cluster_reason = "Clustered by shared themes: tell, your, country’s, tech, startups."
sentiment_response = requests.post(
'https://api.pulsebit.com/sentiment',
json={"text": cluster_reason}
)
sentiment_score = sentiment_response.json().get('score')
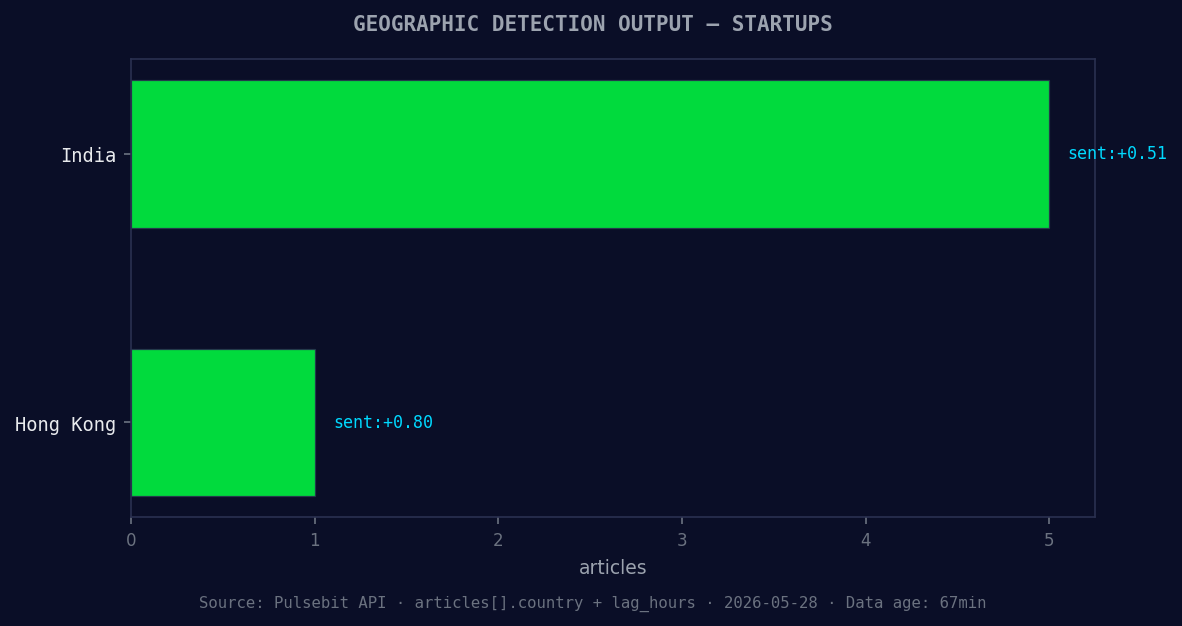
*Geographic detection output for startups. India leads with 5 articles and sentiment +0.51. Source: Pulsebit /news_recent geographic fields.*
print("Meta-sentiment score: ", sentiment_score)
In this code, we first filter articles by language. Then, we run the cluster reason string through our sentiment endpoint to score the narrative framing itself. This step is crucial; it gives us insight into how the narrative around startups is evolving beyond just the raw data.
Now, let’s explore three specific builds you can implement tonight that leverage this pattern:
Startup Sentiment Dashboard: Create a dashboard that tracks sentiment scores for "startups" filtered by the English language. Set a threshold to alert you when the sentiment score drops below +0.25, indicating a potential shift in market confidence.
Meta-Sentiment Analysis Trigger: Develop an automated alert system that triggers whenever the meta-sentiment score on narratives containing "tell your country’s tech startups" falls below +0.5. This will help you catch emerging negative trends before they escalate.
Geo-Sensitive Trend Tracker: Build a tool that monitors sentiment shifts in tech across different languages. Use the geo filter to track articles in both English and German, and set a threshold where if the sentiment score diverges by more than 0.3 points, it highlights an emerging topic that needs further investigation.
You can get started by visiting our documentation. With this setup, you can copy-paste and run your own analysis in under 10 minutes. Don't let your pipeline fall behind!

Top comments (0)